用自定义斜杠命令封装常用提示词
本篇将带你:
学会如何把长提示词封装成只有一两个单词的命令;
利用 $ARGUMENTS 加参数,让命令变得灵活多变。
用 !(执行脚本)和 @(引用文件)为命令注入实时上下文。
1. 为什么我们需要“自定义命令”?
想象一下,你每天晨跑前都有一套固定的热身动作:压腿、拉伸、开合跳…… 动作繁琐,顺序还不能错。每天都得努力去回忆这一套动作,是不是很累?
有一天,你把这套动作录成一段语音指令,命名为 “/warmup”。从此以后,你只需要按一下播放键,身体跟着做就行了。
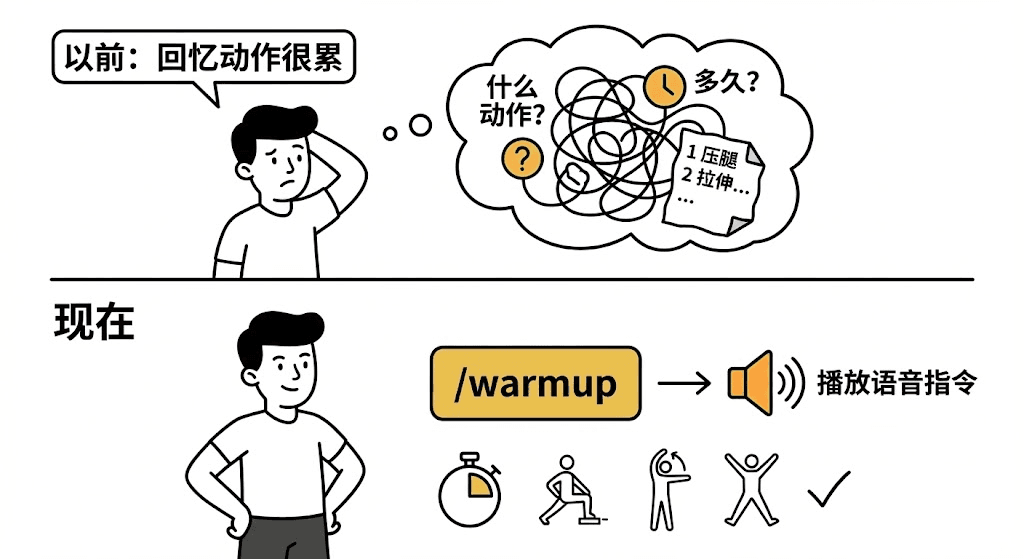
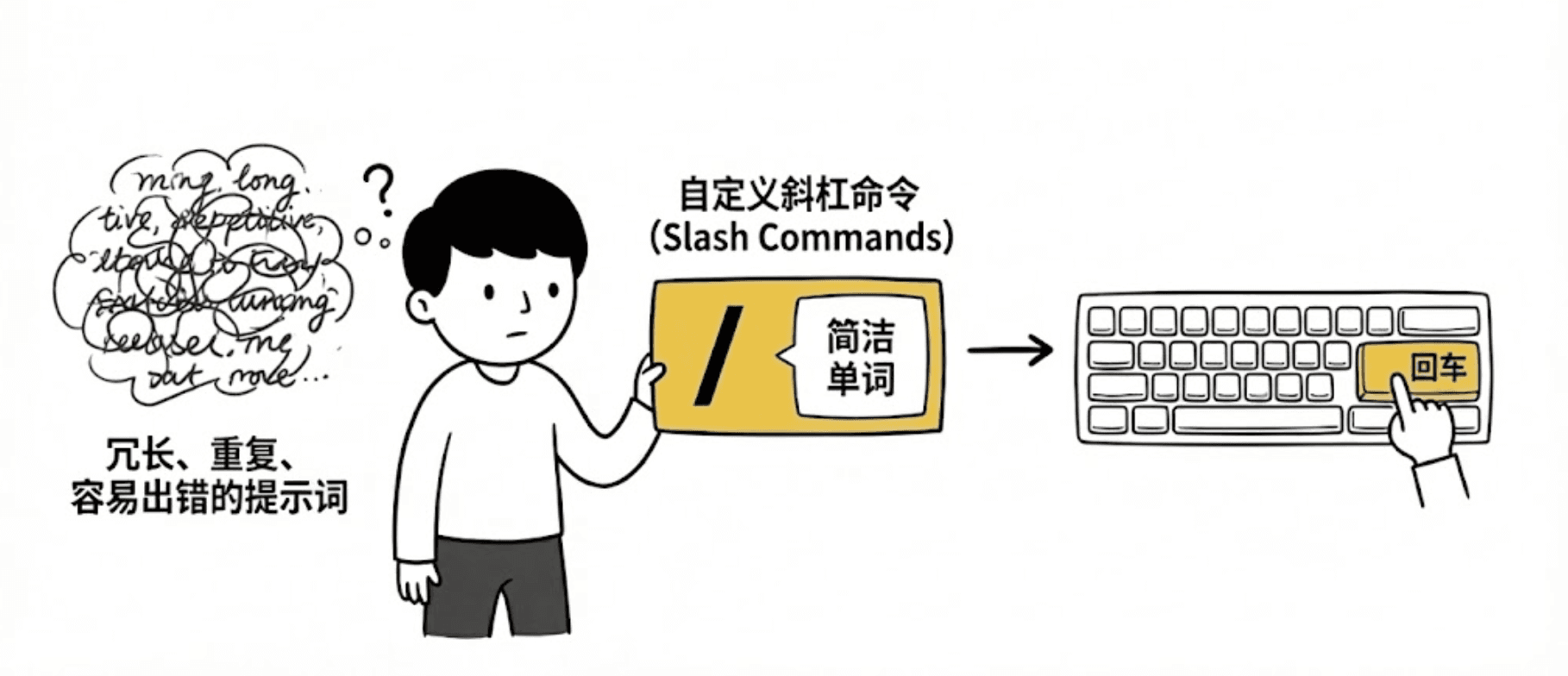
自定义斜杠命令(Slash Commands)就是这个逻辑。
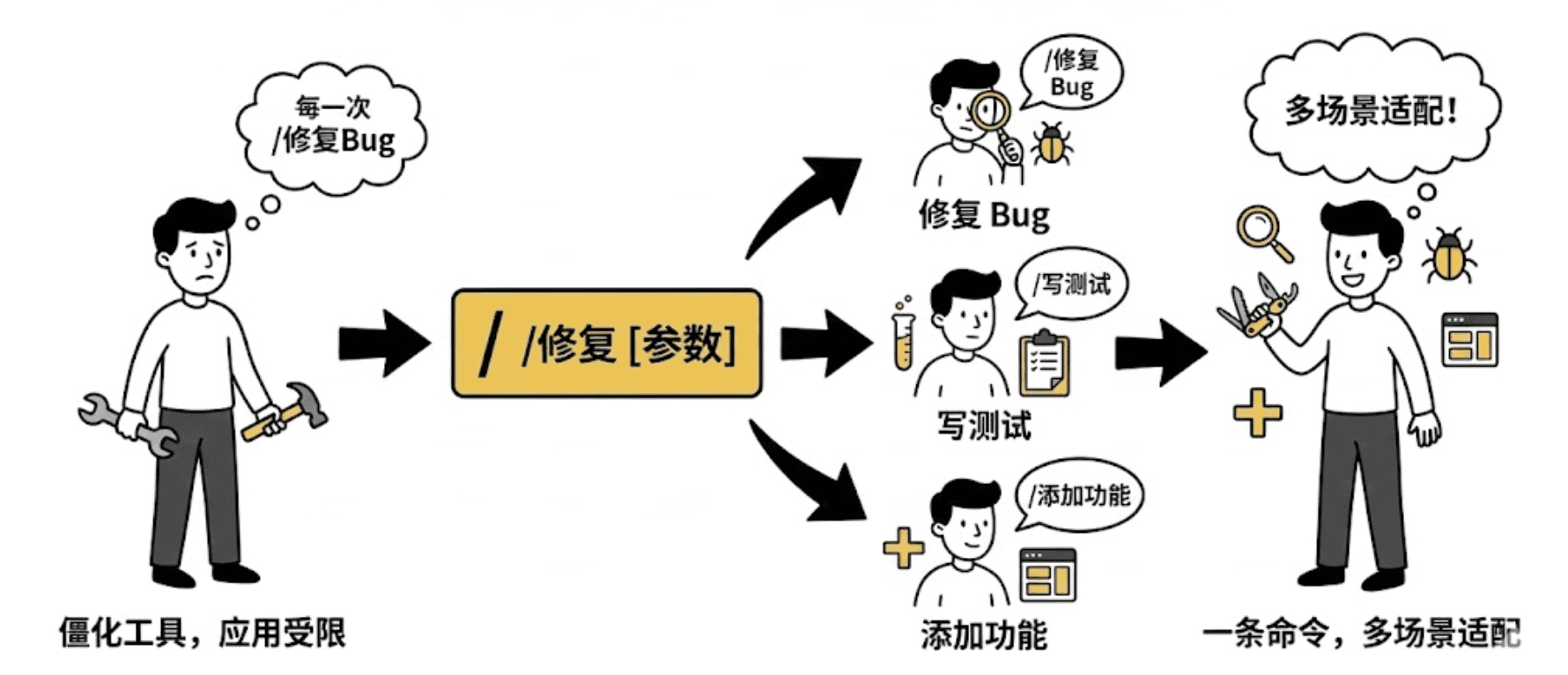
它能把你那些冗长、重复、容易出错的提示词,封装成一个简洁的单词。需要时,敲一下回车就能执行。
它的核心价值在于:
拒绝重复:一次编写,无限复用。告别每次手打几百字 Prompt 的痛苦。
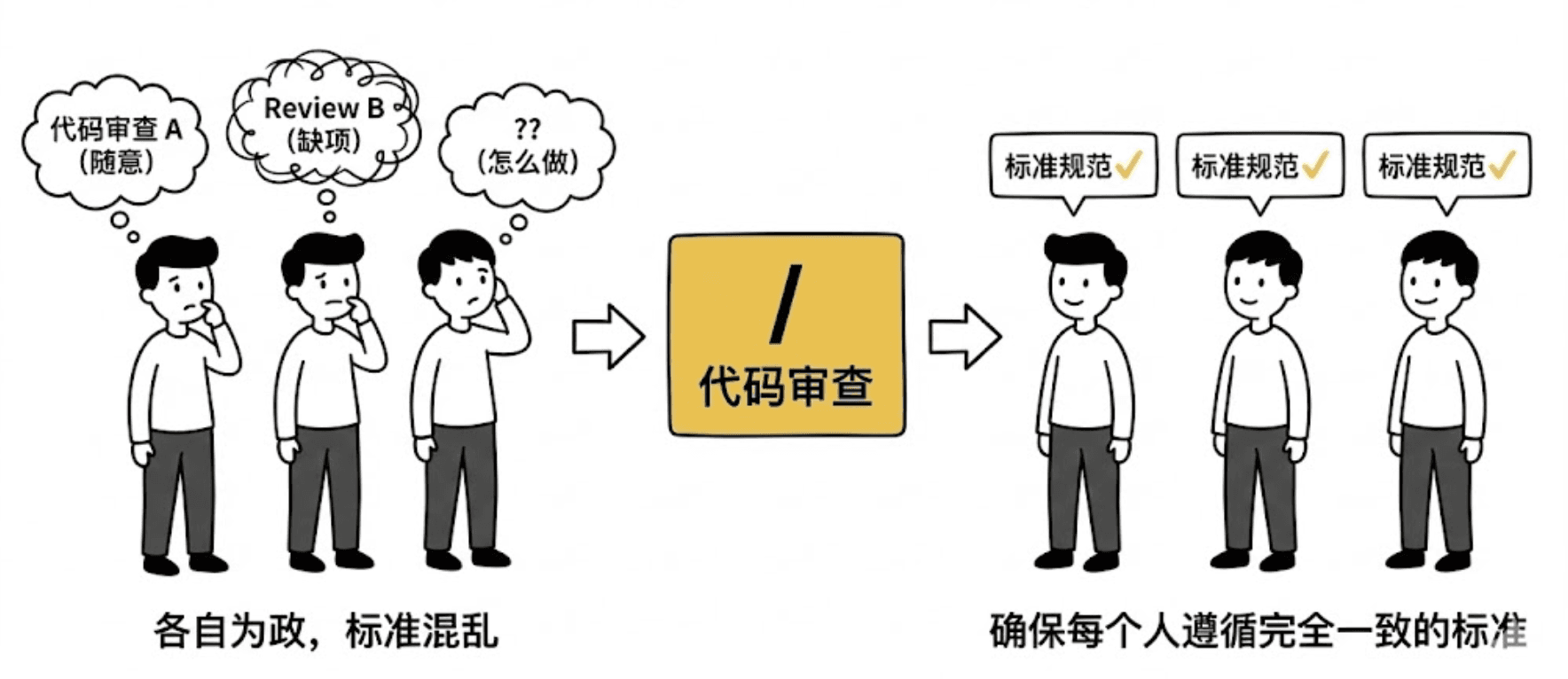
统一标准:确保团队里的每个人,在执行“代码审查”或“提交代码”时,都遵循完全一致的标准。
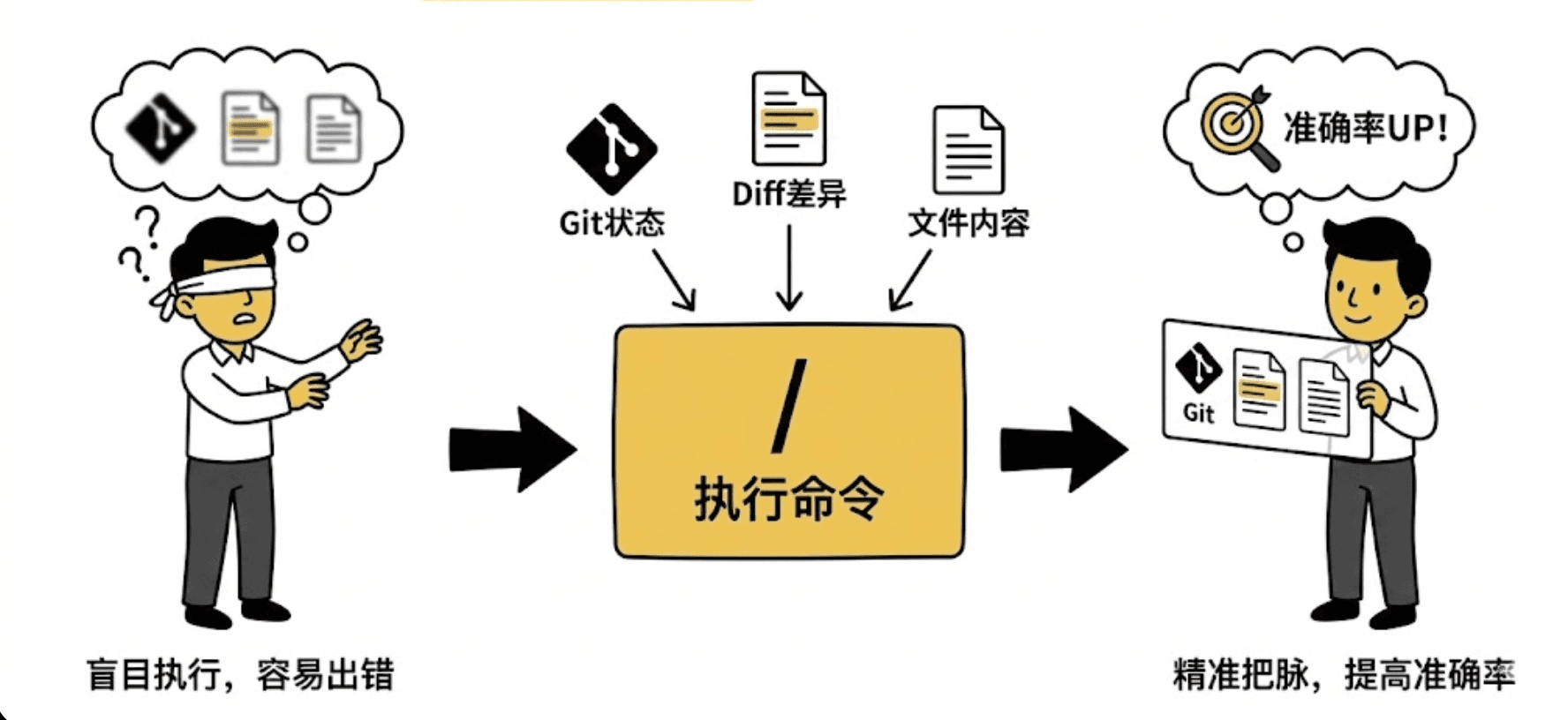
自动感知:它可以在执行前,自动拉取 Git 状态、Diff 差异、文件内容。帮 Claude Code “把脉”,极大提高任务准确率。
灵活变通:支持传入参数,同一条命令可以适配修复 Bug、写测试等多种场景。
2. 基本语法与结构
2.1 文件放在哪?
所有的自定义命令本质上都是一个 Markdown 文件。它同样划分为了:
用户命令(存入 ~/.claude/commands/,全局生效);
项目命令(存入.claude/commands/,仅本项目生效)。
举个例子**: **如果文件名是 fix-issue.md,你在对话框里调用的命令就是 /fix-issue。
2.2 参数怎么填?
你可以在 Markdown 文件中预埋“坑位”,等待调用时填入内容:
$ARGUMENTS:全量参数。运行时,它会把你输入在命令后的所有文字,原封不动地替换进去。
$1, $2, $3...:位置参数。如果你输入了多个词(用空格隔开),它们会依次对应第 1、第 2、第 3 个参数。
3. 快速上手:创建你的第一个命令
光说不练假把式。我们来做一个最实用的实战:创建一个 /api-integration 命令,让 Claude code 帮我们自动对接任意第三方 API。
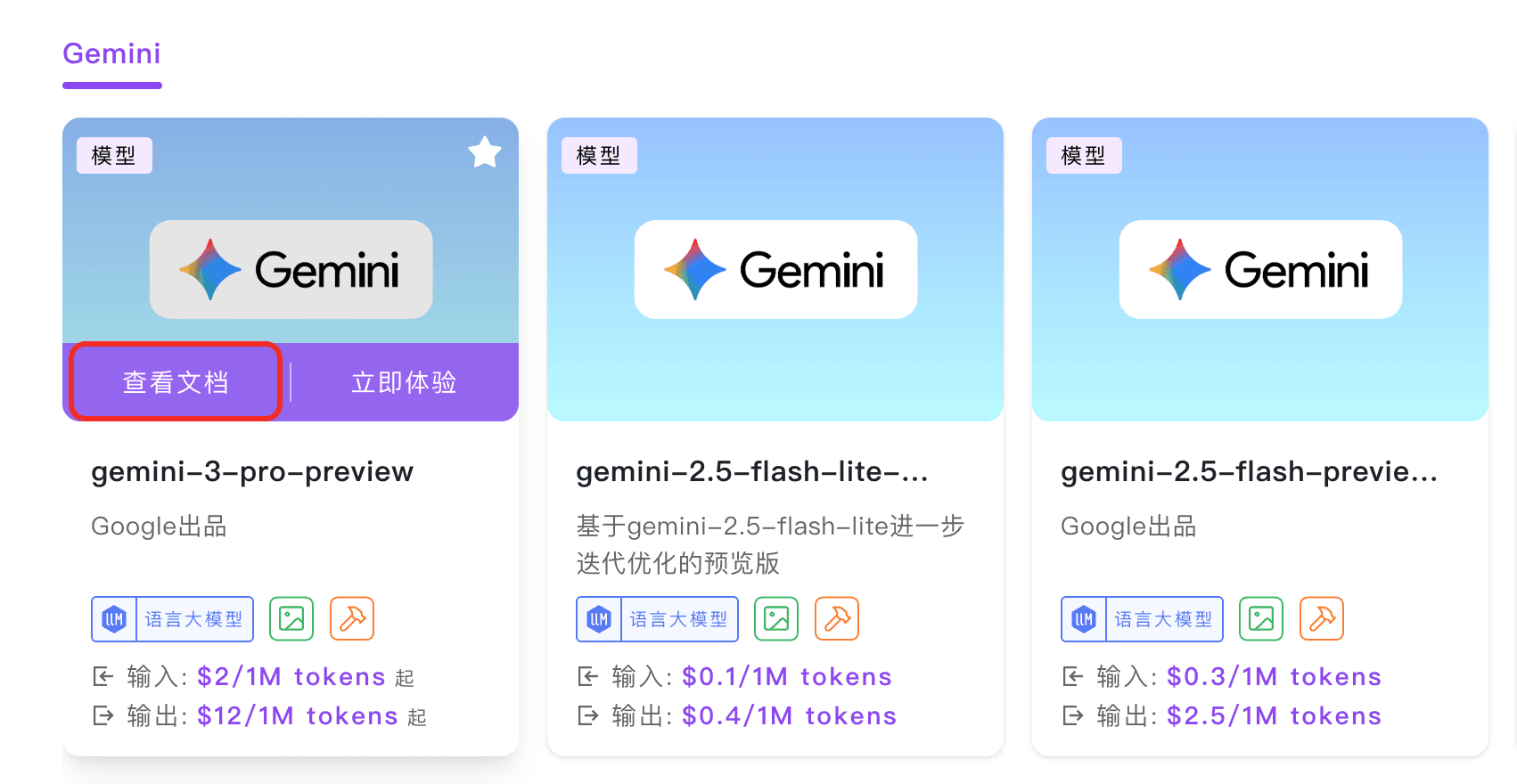
第0步:准备好API文档
进入 302.ai 的「API 超市」,找到你想要接入的模型(比如 Gemini),点击「查看文档」并「复制页面」。

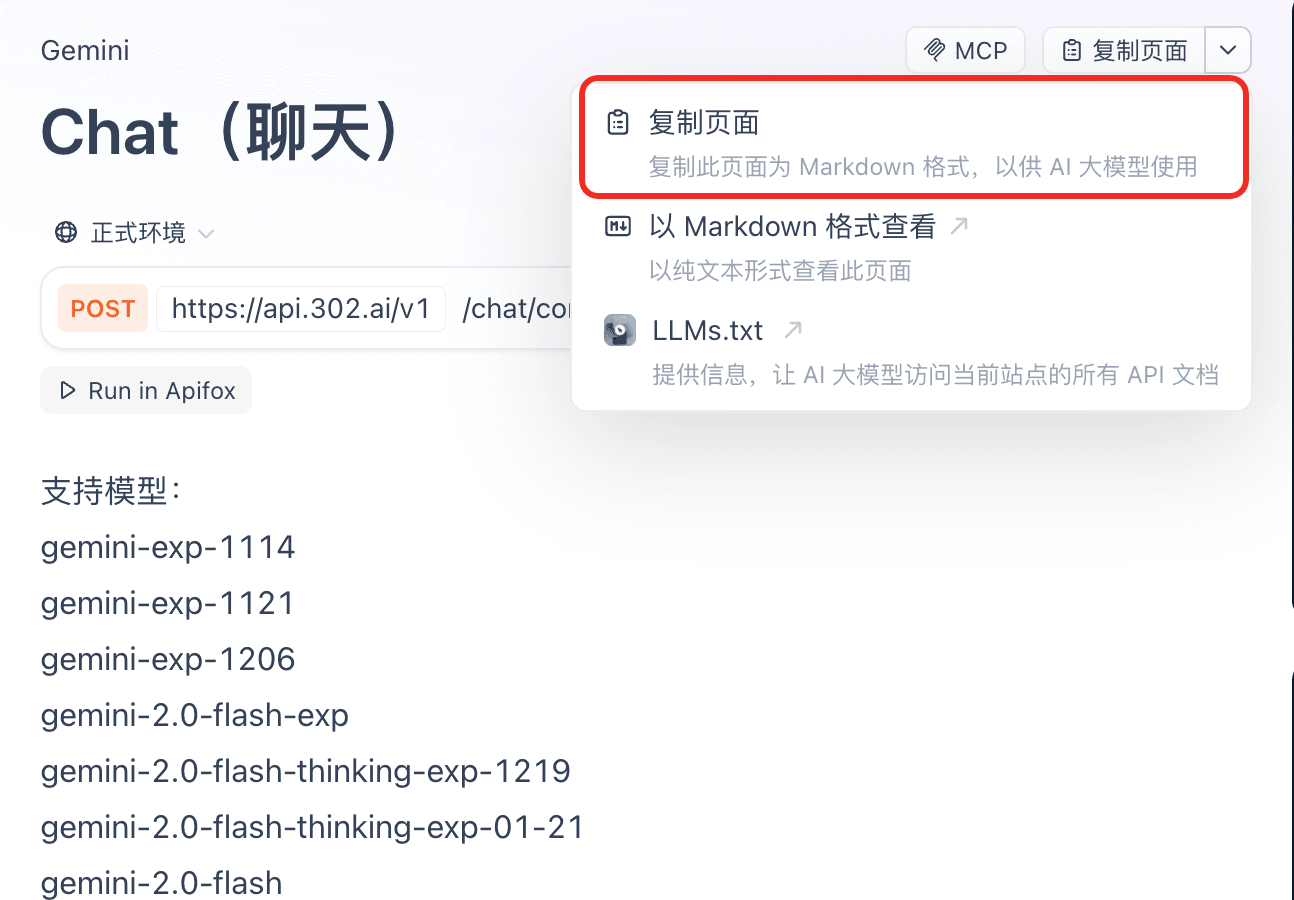
新建一个docs/api/302ai/gemini.md文件,把刚刚复制的内容粘贴进去。
# Chat(聊天)
## OpenAPI Specification
```yaml
openapi: 3.0.1
info:
title: ''
description: ''
version: 1.0.0
paths:
/chat/completions:
post:
summary: Chat(聊天)
deprecated: false
description: "支持模型:\ngemini-exp-1114\ngemini-exp-1121\ngemini-exp-1206\ngemini-2.0-flash-exp\ngemini-2.0-flash-thinking-exp-1219\ngemini-2.0-flash-thinking-exp-01-21\t\ngemini-2.0-flash\ngemini-2.0-flash-lite-preview-02-05\ngemini-2.0-pro-exp-02-05\ngemini-2.5-pro-exp-03-25\ngemini-2.5-pro-preview-03-25\ngemini-2.5-flash-preview-04-17\ngemini-2.5-pro-preview-05-06\ngemini-2.5-pro-preview-05-06-thinking(展示思考过程)\ngemini-2.5-flash-preview-05-20\ngemini-2.5-flash-preview-05-20-nothink(强制关闭思考)\ngemini-2.5-pro-preview-06-05\ngemini-2.5-pro-preview-06-05-thinking(展示思考过程)\ngemini-2.5-pro\t\ngemini-2.5-flash\t\ngemini-2.5-flash-lite-preview-06-17\ngemini-3-pro-preview\n\n\n注意:我们对API的格式进行了改造,兼容了OpenAI的API格式\n\n**价格请查看:https://302.ai/price**"
tags:
- 语言大模型/Gemini
parameters:
- name: Content-Type
in: header
description: ''
required: true
example: application/json
schema:
type: string
- name: Accept
in: header
description: ''
required: true
example: application/json
schema:
type: string
- name: Authorization
in: header
description: ''
required: false
example: Bearer {{YOUR_API_KEY}}
schema:
type: string
requestBody:
content:
application/json:
schema:
type: object
properties:
model:
type: string
description: >-
要使用的模型的 ID。有关哪些模型适用于聊天 API
的详细信息,请参阅[模型端点兼容性表。](https://platform.openai.com/docs/models/model-endpoint-compatibility)
messages:
type: array
items:
type: object
properties:
role:
type: string
content:
type: string
x-apifox-orders:
- role
- content
description: >-
以[聊天格式](https://platform.openai.com/docs/guides/chat/introduction)生成聊天完成的消息。
temperature:
type: integer
description: >-
使用什么采样温度,介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如
0.2)将使输出更加集中和确定。 我们通常建议改变这个或`top_p`但不是两者。
top_p:
type: integer
description: >-
一种替代温度采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果。所以 0.1 意味着只考虑构成前
10% 概率质量的标记。 我们通常建议改变这个或`temperature`但不是两者。
'n':
type: integer
description: 为每个输入消息生成多少个聊天完成选项。
stream:
type: boolean
description: >-
如果设置,将发送部分消息增量,就像在 ChatGPT
中一样。当令牌可用时,令牌将作为纯数据[服务器发送事件](https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events/Using_server-sent_events#Event_stream_format)`data:
[DONE]`发送,流由消息终止。[有关示例代码](https://github.com/openai/openai-cookbook/blob/main/examples/How_to_stream_completions.ipynb),请参阅
OpenAI Cookbook 。
stop:
type: string
description: API 将停止生成更多令牌的最多 4 个序列。
max_tokens:
type: integer
description: 聊天完成时生成的最大令牌数。 输入标记和生成标记的总长度受模型上下文长度的限制。
presence_penalty:
type: number
description: >-
-2.0 和 2.0 之间的数字。正值会根据到目前为止是否出现在文本中来惩罚新标记,从而增加模型谈论新主题的可能性。
[查看有关频率和存在惩罚的更多信息。](https://platform.openai.com/docs/api-reference/parameter-details)
frequency_penalty:
type: number
description: >-
-2.0 和 2.0 之间的数字。正值会根据新标记在文本中的现有频率对其进行惩罚,从而降低模型逐字重复同一行的可能性。
[查看有关频率和存在惩罚的更多信息。](https://platform.openai.com/docs/api-reference/parameter-details)
logit_bias:
type: 'null'
description: >-
修改指定标记出现在完成中的可能性。 接受一个 json 对象,该对象将标记(由标记器中的标记 ID 指定)映射到从
-100 到 100 的关联偏差值。从数学上讲,偏差会在采样之前添加到模型生成的 logits
中。确切的效果因模型而异,但 -1 和 1 之间的值应该会减少或增加选择的可能性;像 -100 或 100
这样的值应该导致相关令牌的禁止或独占选择。
user:
type: string
description: >-
代表您的最终用户的唯一标识符,可以帮助 OpenAI
监控和检测滥用行为。[了解更多](https://platform.openai.com/docs/guides/safety-best-practices/end-user-ids)。
required:
- model
- messages
x-apifox-orders:
- model
- messages
- temperature
- top_p
- 'n'
- stream
- stop
- max_tokens
- presence_penalty
- frequency_penalty
- logit_bias
- user
example:
model: gemini-1.5-pro
messages:
- role: user
content: 你是谁
responses:
'200':
description: ''
content:
application/json:
schema:
type: object
properties:
id:
type: string
object:
type: string
created:
type: integer
choices:
type: array
items:
type: object
properties:
index:
type: integer
message:
type: object
properties:
role:
type: string
content:
type: string
required:
- role
- content
x-apifox-orders:
- role
- content
finish_reason:
type: string
x-apifox-orders:
- index
- message
- finish_reason
usage:
type: object
properties:
prompt_tokens:
type: integer
completion_tokens:
type: integer
total_tokens:
type: integer
required:
- prompt_tokens
- completion_tokens
- total_tokens
x-apifox-orders:
- prompt_tokens
- completion_tokens
- total_tokens
required:
- id
- object
- created
- choices
- usage
x-apifox-orders:
- id
- object
- created
- choices
- usage
headers: {}
x-apifox-name: OK
security: []
x-apifox-folder: 语言大模型/Gemini
x-apifox-status: released
x-run-in-apifox: https://app.apifox.com/web/project/4012774/apis/api-147522041-run
components:
schemas: {}
securitySchemes:
apiKeyAuth:
type: apikey
in: header
name: Authorization
servers:
- url: https://api.302.ai
description: 正式环境
- url: https://api.302ai.cn
description: 国内中转
security: []
**第 1 步:创建命令目录**
打开终端(Terminal),输入以下命令,给命令文件安个家:
```markdown
mkdir -p .claude/commands
第 2 步:编写命令逻辑
现在,我们要告诉 Claude Code 如何处理这份文档。在终端输入以下命令:
echo "基于提供的API文档($ARGUMENTS),创建一个完整的API调用封装。包括:1) 提取认证方式、请求方法、URL、请求体结构;2) 创建一个使用该API的简洁函数/类,支持传入动态参数;3) 添加错误处理和必要的类型定义;4) 在工具栏添加调试按钮,点击弹出完整的API调试窗口,可配置API Key、修改请求参数以及查看响应内容。" > .claude/commands/api-integration.md
它会自动生成一个 .md 文件:

第3步:一键调用
接下来,在 Claude Code 的对话框中输入:
/api-integration docs/api/302ai/gemini.md
第4步:见证效果
Claude Code 在接收参数,组装成完整的指令后,就会开始工作。
它会读取你指定的 API 文档,快速生成一个可用的 API 调用封装,并提供一个可视化的调试窗口。


顺利的话,我们就可以在运行起来的页面的工具栏处,找到调试入口。
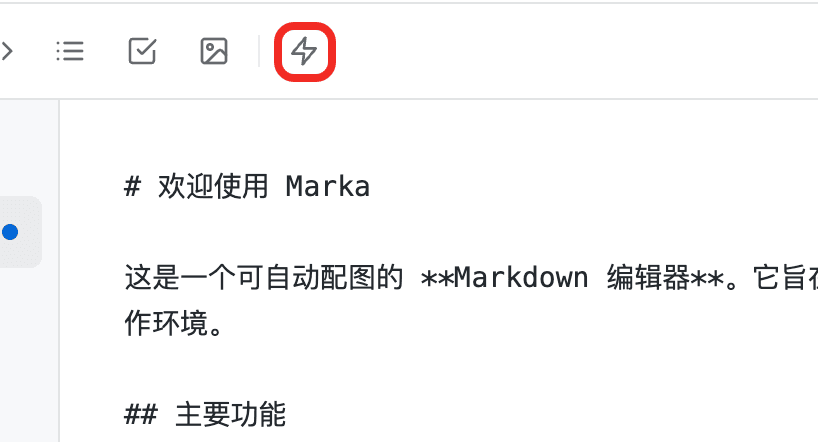
点击入口,会弹出一个可视化调试窗口(注意,实际生成的页面可能有所不同):
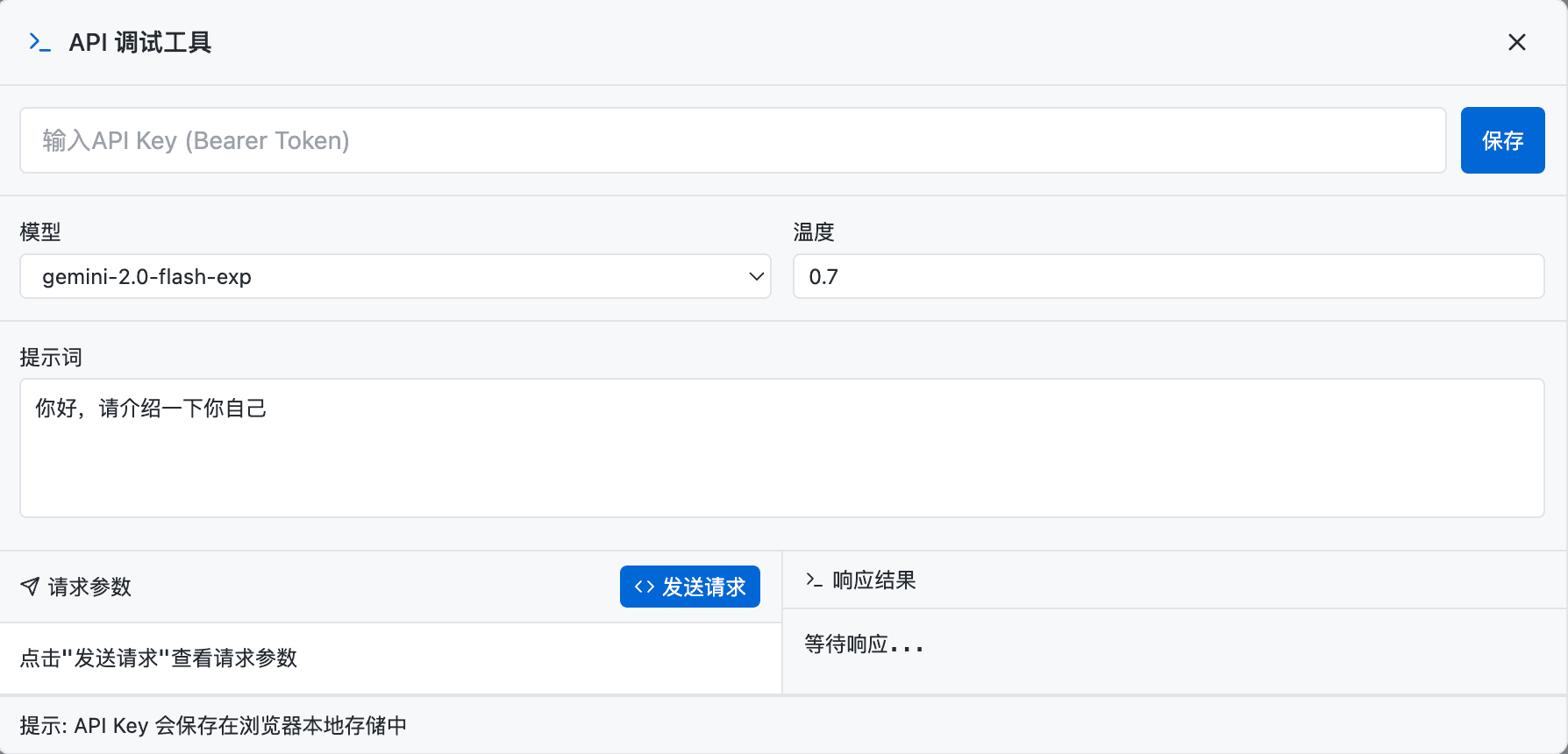
先设置好你的 302.ai API Key:
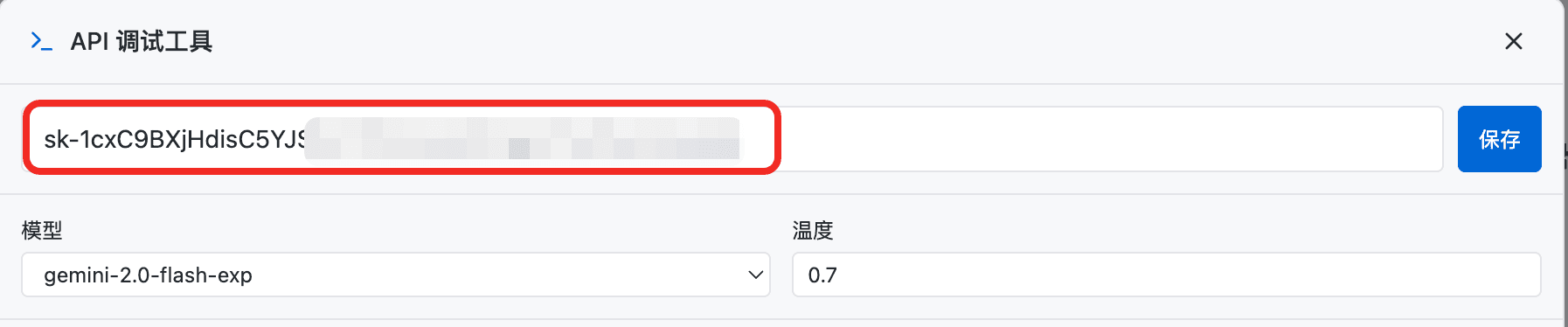
再点击「保存」按钮,这一步会把302.ai API Key 保存在浏览器本地存储中,不用每次都重新输入:
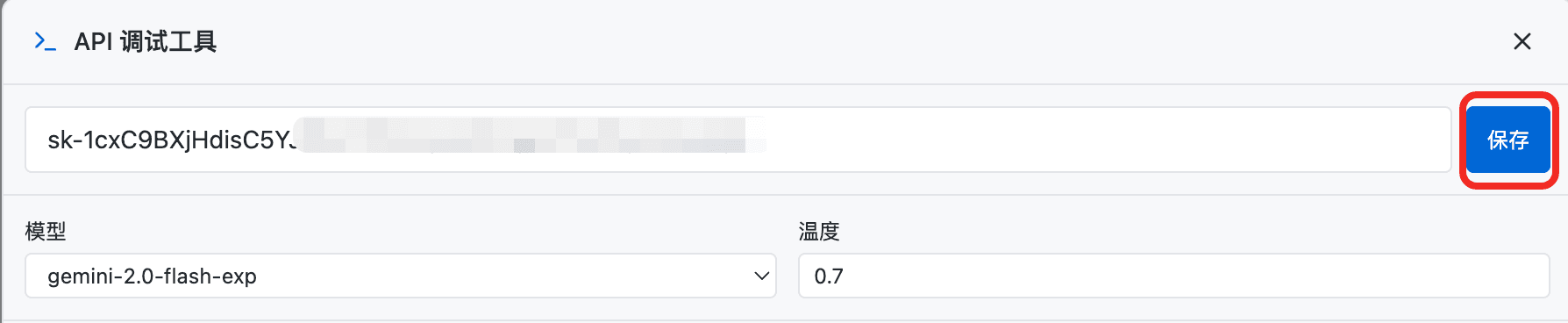
点击「发送请求」按钮,查看是否有正确响应:
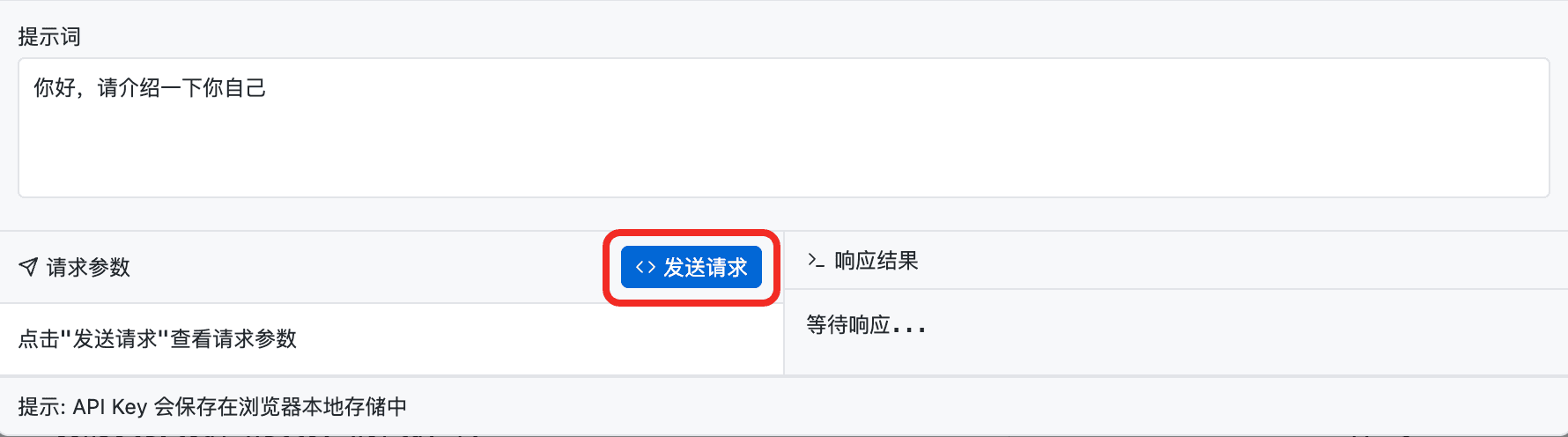
恭喜你,你只用了一行命令,就完成了复杂的 API 接入工作。
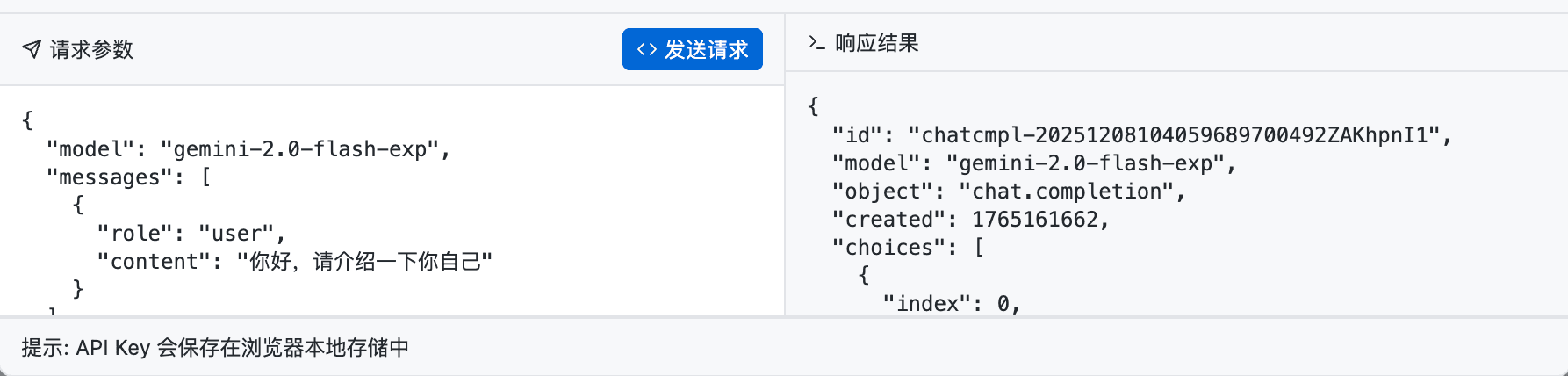
现在,“Marka”项目已经具备了与大语言模型交互的能力,这将为我们后续添加“自动配图”功能打下基础。
4. 进阶:使用Frontmatter配置“说明书”
想让你的命令更专业?可以在文件顶部添加 Frontmatter(元数据),相当于一份“配置说明书”。
---
allowed-tools: Bash(git add *), Bash(git status *), Bash(git commit *)
argument-hint: [更改的内容]
description: 创建一条 Git 提交记录。
model: claude-3-5-sonnet-20240620
---
请创建一条 Git 提交,更改内容为:$ARGUMENTS
字段解析:
点击图片可查看完整电子表格
5. 高级技巧:注入上下文
这是自定义命令最强大的部分,分为“静态”和“动态”两种。
5.1 技巧 1:使用 @ 注入“静态知识”
当我们每次都需要 Claude Code 参考一些固定的文档(如流程、规范)时,可以使用 @文件路径 来实现。
场景:基于规范的“代码找茬”
A. 首先,把以下这份《API 接口设计规范》保存到 docs/spec 目录下。
# API 接口设计规范
## 命名与文件结构 (Naming & Structure)
- **文件命名**: 按照领域/资源命名,例如 `userService.ts`, `orderService.ts`。
- **函数命名**: 采用 `动词 + 名词` 的形式,动作明确。
- `fetchUser` / `getUser` (获取)
- `createUser` / `submitOrder` (创建)
- `updateProfile` (更新)
- `deleteItem` (删除)
- **类型定义**: 所有的 Request 参数和 Response 响应都必须有对应的 TypeScript Interface 定义,且通常与 API 函数在同一文件中导出,或引用统一的 `types/` 目录。
## 编码标准 (Coding Standards)
### 1. 强类型契约
- **禁止 `any`**: 必须为每一个 API 调用的返回值定义明确的 Interface。
- **DTO 模式**: 如果后端返回的数据结构混乱,必须在此层进行清洗(Transform),返回给前端组件的一定是干净、驼峰命名的标准数据。
### 2. 请求封装
- **使用统一实例**: 必须导入并使用项目统一配置的 HTTP 客户端实例 (如 `src/utils/http.ts` 中的 axios instance),禁止直接使用 `fetch` 或新建 axios 实例。
- **RESTful 风格**: 遵循 REST 语义,正确使用 GET/POST/PUT/DELETE 方法。
### 3. 错误处理
- **透传错误**: 除非需要进行特定格式的转换,否则不要在此层 `catch` 错误。让错误抛出,交给调用方 (React Query 或 UI 组件) 处理。
### 4. 注释补充
- **注释即文档**: 每个导出函数上方必须有注释,说明该接口对应后端哪个 URL 以及主要用途。
### 5. 参数定义
- **参数解构**: 如果参数超过 2 个,请使用对象解构作为函数参数。
B. 然后,创建一个新的命令 review_api.md:
我是一名编程初学者,请帮我优化 `$ARGUMENTS` 下的接口代码。
请参考 @docs/spec/api-design-spec.md 作为最佳实践标准。
请一步步分析我的代码:
1. **指出不足**:告诉我哪里写得不好,违反了哪条规范?
2. **解释原因**:为什么规范里要求这样做?(例如:这样做对维护有什么好处?)
3. **演示优化**:展示重构后的代码,并加上详细注释。
当你调用 /review_api 时,Claude Code 会先去阅读 @ 引用的规范文件。
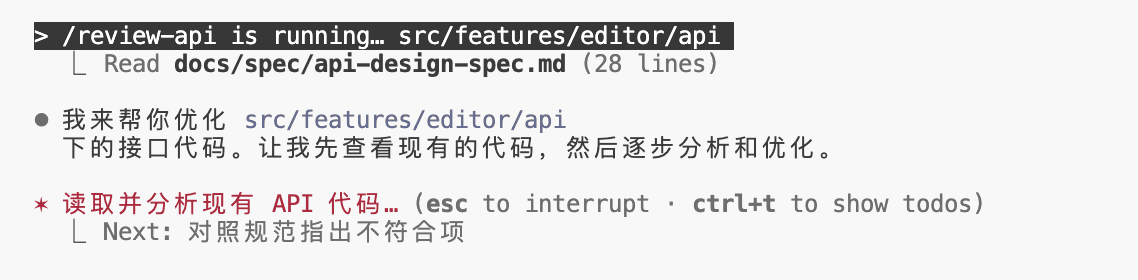
然后,它会拿着这把“尺子”,去衡量我们刚刚对接第三方 API 时实现的代码,指出有哪里不符合规范,并告诉你如何改进。


5.2 技巧 2:使用 ! 注入“实时动态”
这是自定义命令最强大的功能,没有之一。
通过 !command 格式,可以让 Claude Code 在执行提示词前,先在你的电脑上运行一段 Bash 脚本。
这个脚本的输出结果,会被自动捕获,作为上下文的一部分,一起传递给 Claude Code。
场景示例:自动生成 Git 提交信息
A. 首先,创建以下文件:~/.claude/commands/git-commit.md
---
allowed-tools: Bash(git add:*), Bash(git status:*), Bash(git commit:*)
description: 根据当前的 Git 状态生成一条提交信息并提交代码。
---
# 上下文信息
- 当前 Git 状态: !`git status`
- 当前代码变更 (暂存区与工作区): !`git diff HEAD`
- 当前所在分支: !`git branch --show-current`
- 最近 10 条提交记录: !`git log --oneline -10`
# 你的任务
请基于以上的代码变更和项目历史,为我撰写一条清晰、规范的 Git 提交信息并提交代码。
B. 接着,只需输入 /git-commit,剩下的都会帮你自动完成:
执行命令:帮你跑 git status 和 git diff。

获取修改:看了你改了哪些文件、哪几行代码。
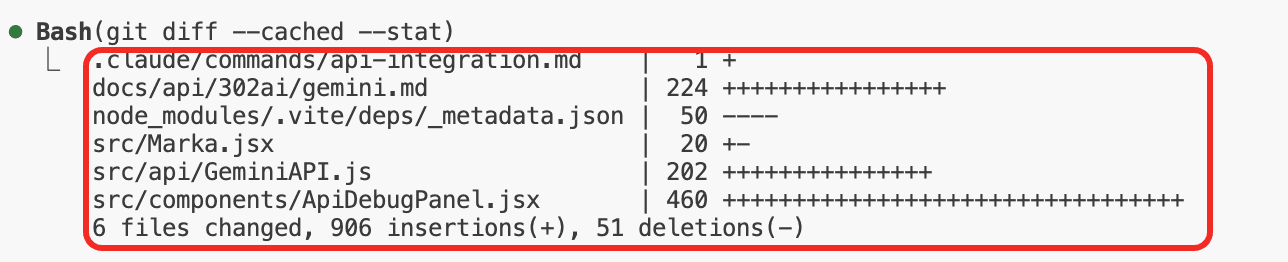
最终产出:结合变更内容和历史记录,生成一条提交信息:feat(api): 集成 302.ai Gemini API。

💡 给读者的建议
最后,关于自定义命令,我有几条建议想送给你:
**痛点即信号:**不要为了写命令而写命令。当你发现自己第三次手动输入同一段冗长的提示词时,那就是创建新命令的最佳时机。
**先僵化,后优化:**不要一上来就追求完美支持各种参数。先针对具体问题写一个“一次性”脚本。发现好用后,再把变量替换成 $ARGUMENTS 变成通用工具。
**独乐乐不如众乐乐:**如果你正在和别人协作,可以把命令提交到 Git 仓库 (.claude/commands/)。你的队友拉取到代码后,也能立刻拥有这套强大的工具箱。 一人栽树,全队乘凉。
用 Hook 构建一个“自动化代码生产线”
本篇将带你:
搞懂 Hook(钩子)到底是个什么黑科技。
了解 Hook 能在 Claude Code 里自动帮你跑腿做哪些事。
亲手配置你的第一个自动化 Hook,从此告别重复劳动。
1. Hook 是什么?
我们先来回顾一个熟悉的场景:每次写完代码,你是不是都要手动执行一系列“收尾工作”? 比如格式化、测试、生成文档、提交 Git……
这些事单做都不难,但它们麻烦、重复、且容易忘记。
如果有一个系统,能在你写完代码的那一刻,自动替你完成这些琐事,是不是就省心多了?
Hook 的作用,就是让 Claude Code 变成这个“贴心的自动化助手”。
你可以把 Hook 想象成 家里门口的衣帽架:
衣帽架 = Claude Code 的整个自动化流程(已经设计好结构和节点)
一个个钩子 = Hook 事件点(系统预留的“可以挂东西的位置”)
你挂上去的物品 = 你想自动执行的任务(脚本、命令、检查)
衣帽架本体不动,但你可以往每个钩子挂任意东西:雨伞、围巾、包、钥匙……
Hook 系统也是同理:不同节点的“钩子”已经准备好了,你只要把你的自动化逻辑“挂”上去就行。
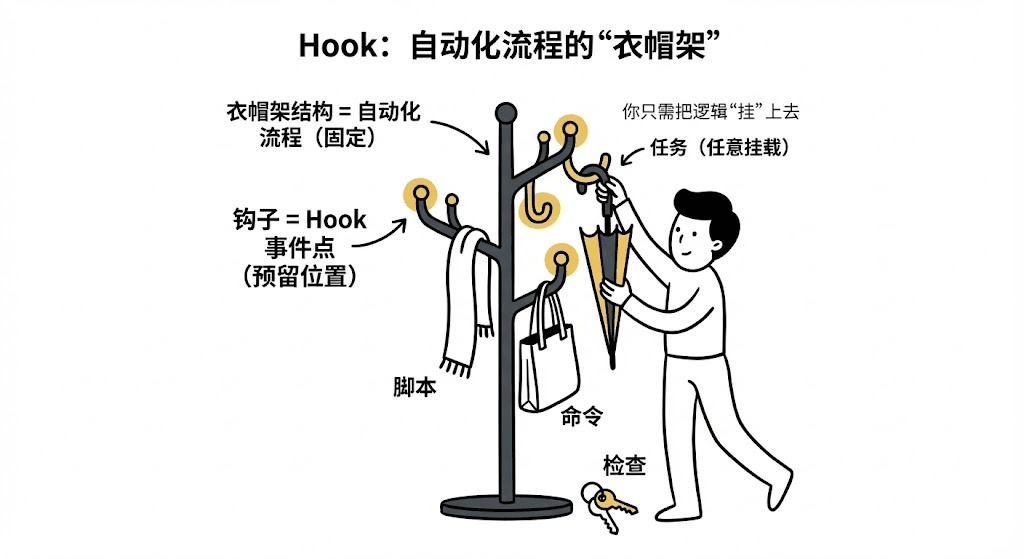
这样一来,你不用修改 Claude Code 的源码,就能将自己的个性化行为“挂”上去,实现深度定制。
2. 为什么要用 Hook?
有人可能会问:“直接在提示词里告诉 Claude Code 不就行了吗?为什么要搞这么复杂?”
我们用一个现实中的生活场景来解释。
你对助理说:“以后发邮件前,麻烦帮我检查一下拼写。” ——这是“建议”。助理忙起来可能会忘记,或者检查得不仔细。
你在邮件系统里设置了一条“规则”:“点击‘发送’按钮时,强制执行拼写检查。如果不通过,禁止发送。”—— 这就是 Hook,100% 自动触发。
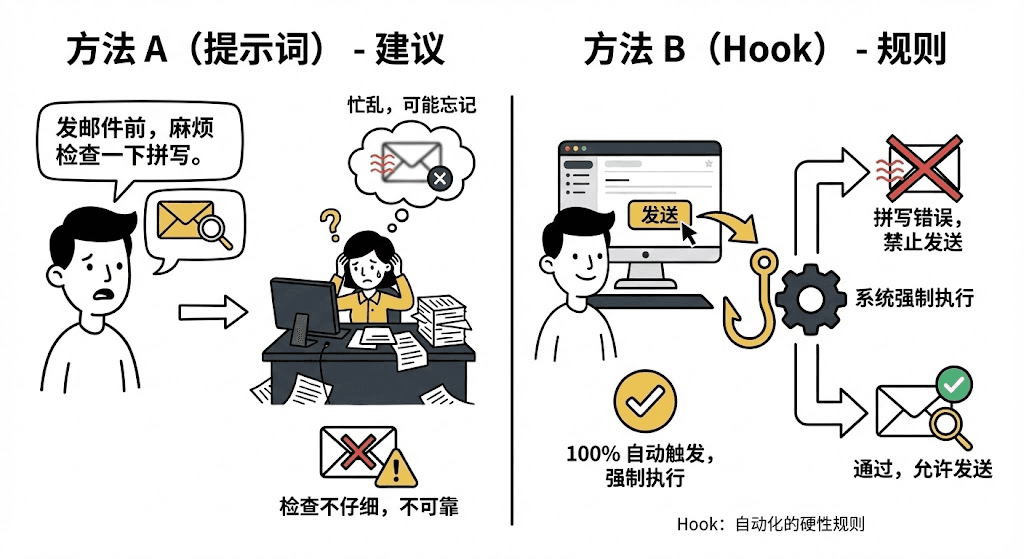
对比总结一下:
点击图片可查看完整电子表格
3. Claude Code 会话的生命周期
要使用 Hook,你得知道 Hook 都能挂在哪里。Claude Code 的每一次会话都会经过一系列的关键节点,就像人的一生有不同的阶段:
点击图片可查看完整电子表格
在这些事件点上,你都能挂上自己的 Hook。
4. Hook配置长什么样?
Hook 是通过一个 JSON 文件来配置的,本质上就是简单的“三段式”:
When:什么事件?
Where:针对哪个工具?
What:执行什么命令?
示例配置:每次 Claude Code 改完代码,自动帮我检查代码风格。
{
"hooks": {
"PostToolUse": [ // 1. When: 工具用完之后
{
"matcher": "Write|Edit", // 2. Where: 仅限“写”和“改”文件的操作
"hooks": [
{
"type": "command",
"command": "$CLAUDE_PROJECT_DIR/.claude/hooks/check-style.sh" // 3. What: 执行脚本
}
]
}
]
}
}
这个配置的含义是:
“嘿 Claude Code,每次你写完或改完文件(PostToolUse + Write|Edit),请立刻执行 check-style.sh 这个脚本,帮我看看代码写得规不规范。”
5. Hook 的“耳”与“口” (I/O)
Hook 不是“闷头干活”的,它可以和 Claude Code 进行双向通信。
5.1 听 :Claude Code 告诉你发生了什么
当 Hook 被触发时,Claude Code 会通过标准输入 (stdin) 传给你一个 JSON 数据包。
输入示例 (PreToolUse):
{
"session_id": "...",
"hook_event_name": "PreToolUse",
"tool_name": "Write",
"tool_input": {
"file_path": "/path/to/file",
"content": "..."
}
}
这个数据包的含义是:
“我要开始写文件了! 文件名是 /src/main.js, 内容是 ...”
你的脚本就可以读取这些信息,判断 file_path是不是敏感文件,content 是否违规等。
5.2 说 :你告诉 Claude Code 该做什么
你的脚本分析完数据后,可以通过打印 (stdout) 一个 JSON 来回应 Claude Code。
输出示例 (PreToolUse):
你的脚本分析完数据后,发现代码里有敏感词,于是回复:
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "deny", // 拒绝执行!
"permissionDecisionReason": "生产环境禁止输出日志。" // 理由
}
}
这个数据包的含义是:
“停!代码里有敏感词 console.log,拒绝执行!理由是:生产环境禁止输出日志。”
收到这个回复后,Claude Code 就会立即停止工具调用,并把你的拒绝理由展示给用户。
6. 实战演练:做一个“防卡死”提示音
接下来,我们来做一个简单但极其实用的 Hook。
痛点:有时候 Claude Code 需要你授权(比如运行命令),但你切出去看网页了,导致它一直在傻等。
目标:当需要授权时,显示一个通知并播放一段音频,提醒你切回来授权操作。就像《火影忍者》中的逆通灵之术把位于妙木山的鸣人召唤回战场一样。
第1步:唤起配置菜单
在 Claude Code 中输入:
/hooks
系统会列出所有可配置的事件列表。
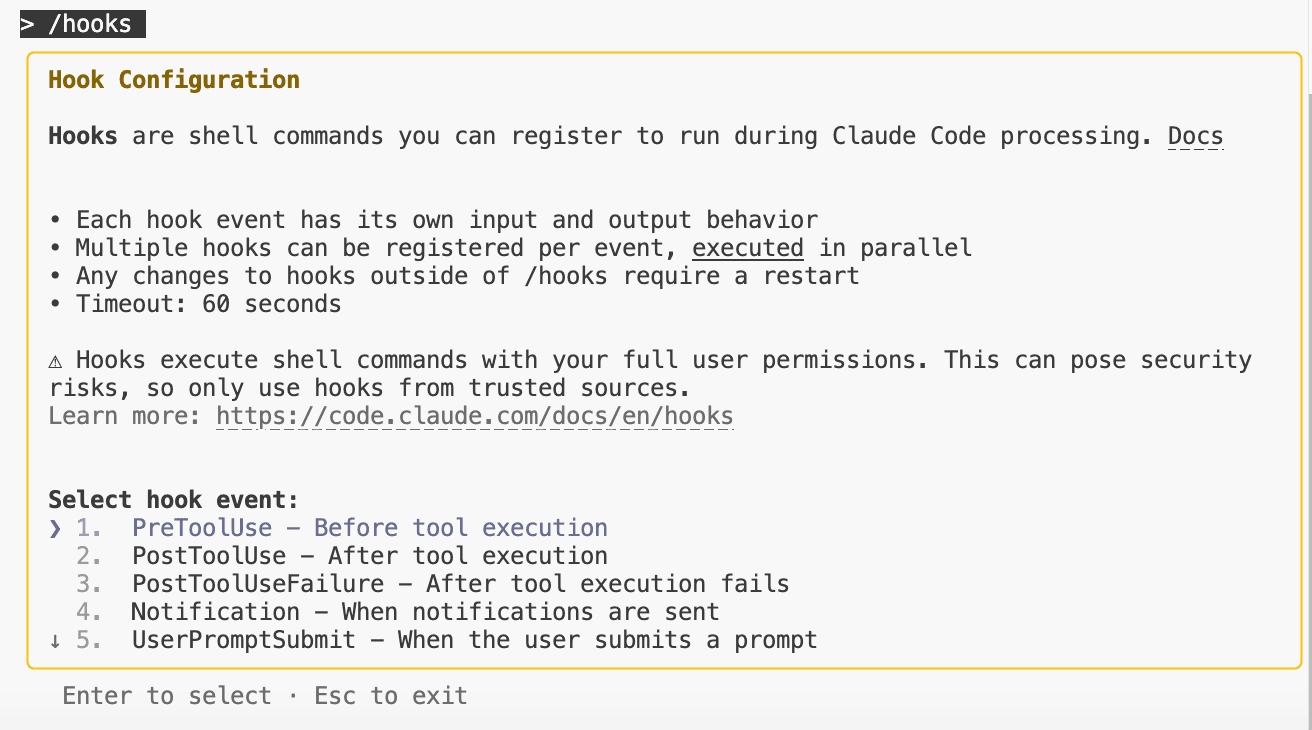
第2步:选择事件
选择 Notification 事件。
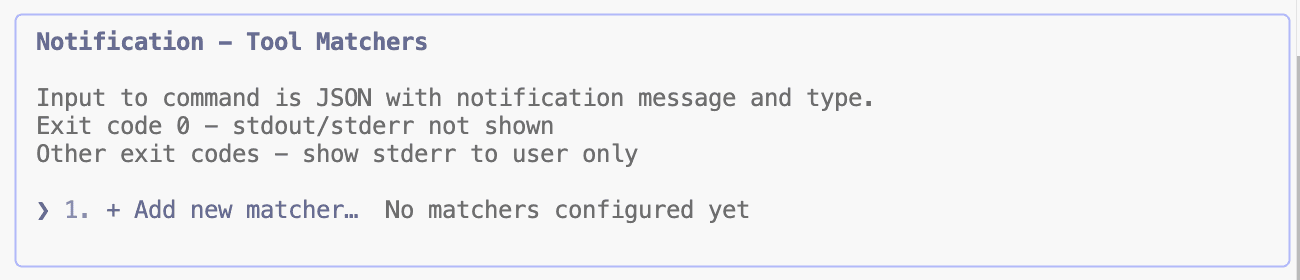
这里会要求你选择一个匹配器(matcher):

permission_prompt - Claude Code 的权限请求通知
idle_prompt - Claude 等待用户输入时的通知(空闲 60 秒以上)
auth_success - 身份验证成功通知
elicitation_dialog - Claude Code 需要 MCP 工具输入时的通知
我们填入 permission_prompt,之后选择添加一个新的 Hook:

第3步:添加命令(以macOS为例)

在输入框中,我们可以搞怪点,粘贴以下命令,这会分别调用系统 API 来播放音频和显示通知。
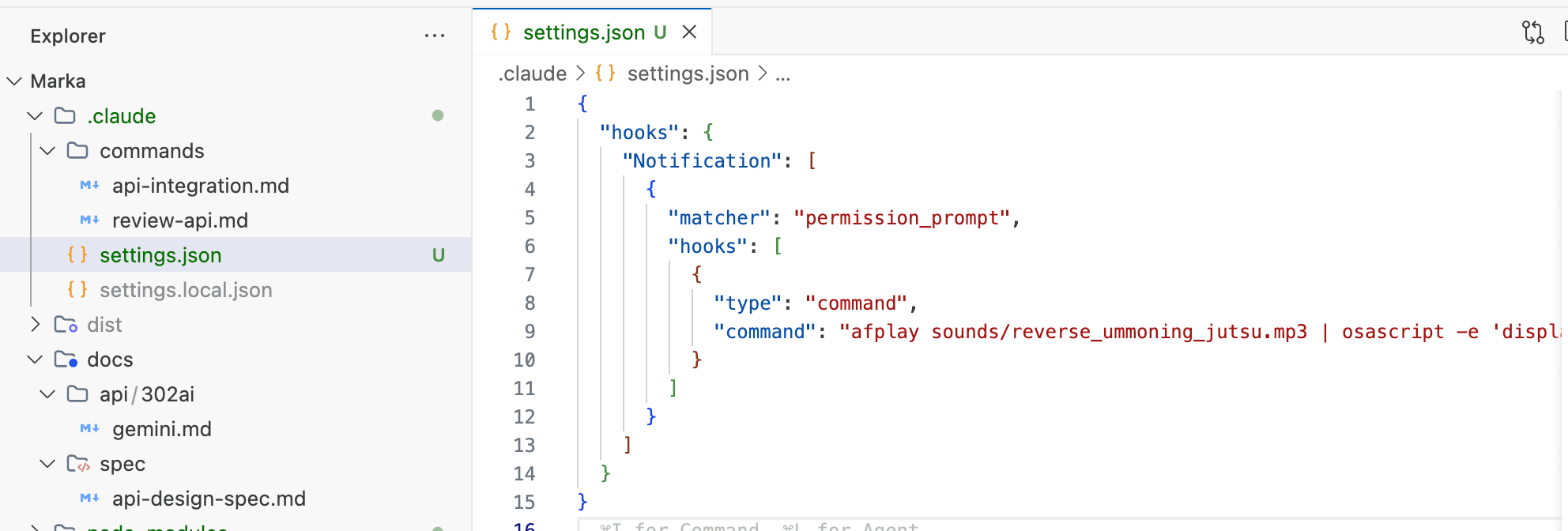
afplay sounds/reverse_ummoning_jutsu.mp3 | osascript -e 'display notification "🐸 ⬇️ 🌀 :・゚✧ 逆通灵之术!!💨 🙍♂️" with title "Naruto!!"'
第4步:保存位置
选择保存到 Project (当前项目) 或 User (全局)。 建议先存到 Project 试运行。

第 5 步:测试 Hook
下次遇到需要授权的操作时,你电脑应该会同时发出一声“逆通灵之术!”,并在右上角显示一条通知提醒。
至此,恭喜你已经成功配置了你的第一个 Hook!
给读者的建议
最后,关于 Hook(钩子),我有几条建议想送给你:
文档不如代码:文档是给人看的,人会犯错;Hook 是给机器跑的,机器永远忠诚。 把“软性的建议”变成“硬性的机制”,是提升工程质量最稳健的方式。
先警告,后拦截: 配置初期,建议先让 Hook 仅输出警告,不要直接阻断流程。等确认规则没有误判后,再开启强制拦截,避免误杀正常操作。
保持轻量: Hook 是同步执行的。 一定要保持脚本的轻量和极速,千万别在这里跑耗时的大任务(如全量打包),否则 Claude Code 会慢到让你怀疑人生。
用 Git Worktree 开启“影分身”模式
本篇将带你:
了解为什么简单地“多开终端”解决不了并行开发的问题
像鸣人一样,用 Git Worktree 创建多个“影分身”工作区
同时指挥两个 Claude Code 实例,互不干扰地处理任务
并行任务的“翻车”现场
先代入一个你可能经历过的场景:
你正沉浸在代码的世界里,灵感如泉涌。突然,两个需求同时砸到了你头上:
任务 A:开发一个新的“深色模式”(需改动配置文件)。
任务 B:紧急修复线上的版本号 Bug(也需改动配置文件)。
你的第一反应也许是:
“这有何难?我开两个终端窗口,启动两个 Claude Code 实例,一边做一个,不就行了?”
听起来很稳,对吧?但这里藏着一个致命的陷阱:如果这两个任务,修改的是同一个文件、甚至同一段代码,会发生什么?
我们来推演一下可能发生的“惨剧”:
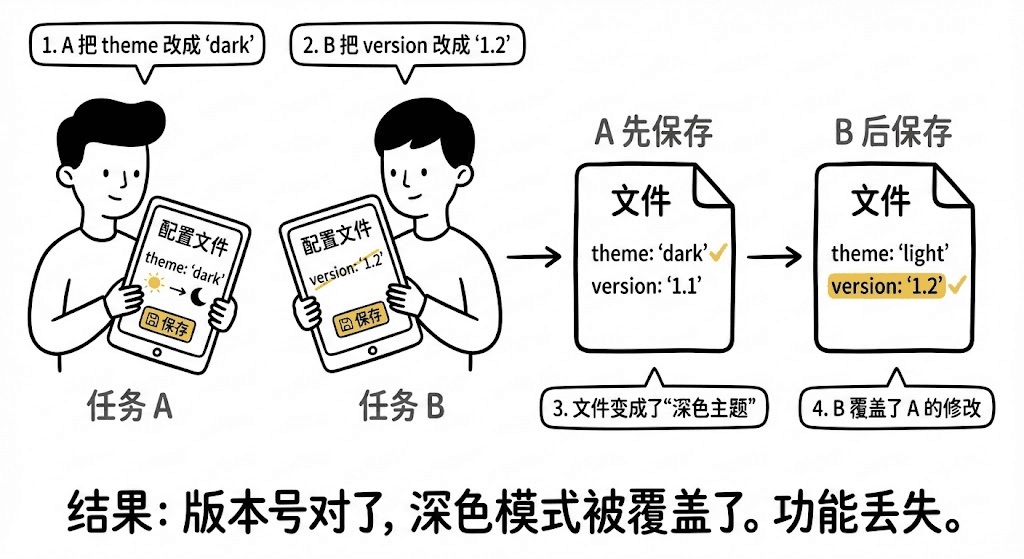
任务 A 把配置文件里的 theme 改成了 "dark"。
任务 B 把配置文件里的 version 改成了 "1.2"。
A 先保存:文件变成了“深色主题”。
B 后保存:由于 B 读取文件时,里面还没有深色主题的代码。B 一保存,直接就覆盖了整个文件。
结果就是:线上版本号改对了,但 A 辛辛苦苦写的“深色模式”代码,被彻底抹除了。更可怕的是,你可能直到上线后才发现功能丢了。
要解决这个问题,我们需要一个能力: 让每个任务在自己的独立空间里运行,互不干扰,就像平行宇宙一样。
这就是 Git 派上用场的地方。
版本控制的基石:Git
如果你完全没了解过 Git,也不要紧,记住这个简单类比:
Git = 程序员的“游戏存档系统”。
玩游戏时,你肯定有过这种操作:
打 Boss 前:先存个档,以此为基准。
打输了? 读取存档,满血复活。
想走另一条剧情线**?** 另存一个新档,放心大胆地去试。
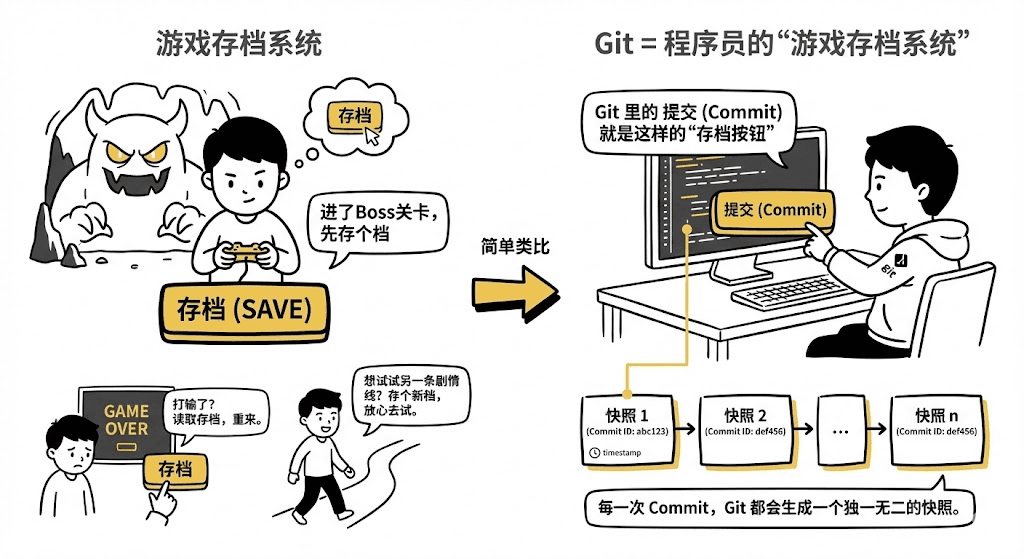
在 Git 里,Commit(提交) 就是那个“存档按钮”。
每一次 Commit,Git 都会把你当前所有的代码状态打包,生成一个独一无二的快照。
有了它,你就能让 Claude Code 放手去改代码。改错了?一键回滚。改乱了?瞬间还原。
Git Worktree 是什么?
如果你看过《火影忍者》,你就能理解 Git Worktree。它和“影分身”的设定几乎完美对应。
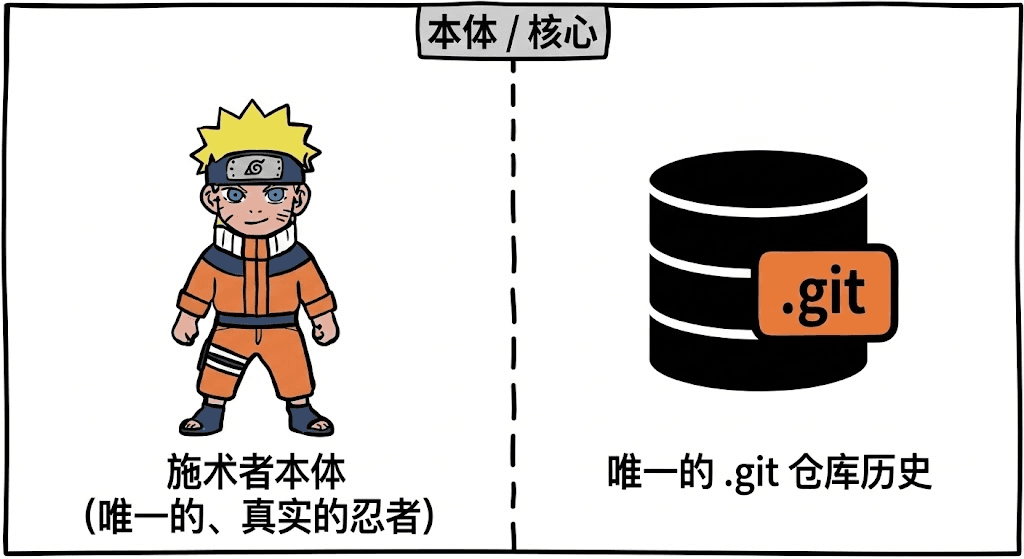
- 本体 =
.git文件夹
首先,在影分身术里,有且只有一个“施术者本体”,也就是唯一真实存在的忍者。
对应到 Git 里,这个“本体”就是唯一的 .git 文件夹。它是所有历史记录和元数据的源头。
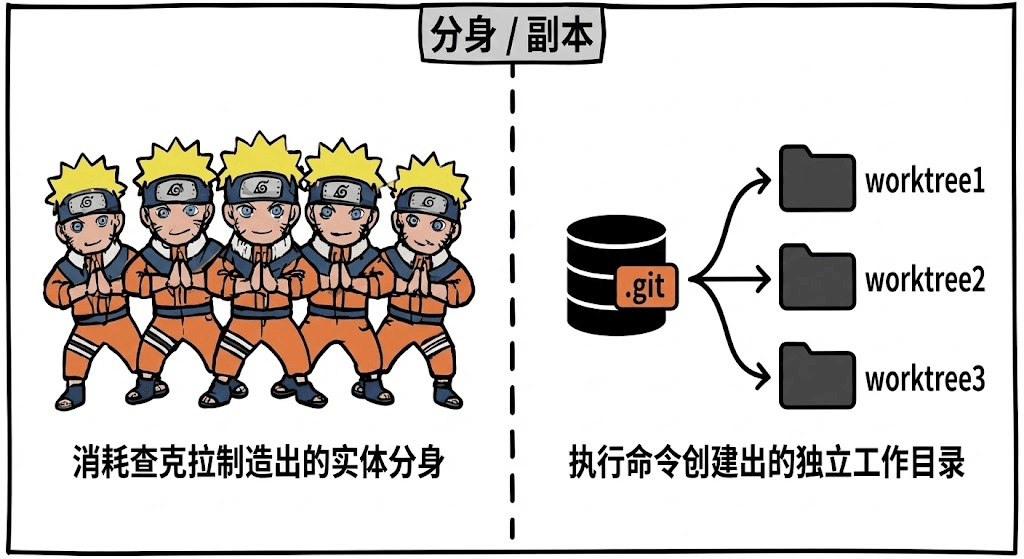
- **施术 = **
git worktree add
影分身会消耗查克拉,制造出多个实体分身;
Git worktree 也类似,只不过它不是靠查克拉,而是通过一条简单的 git worktree add 命令,生成多个互相独立的工作目录。
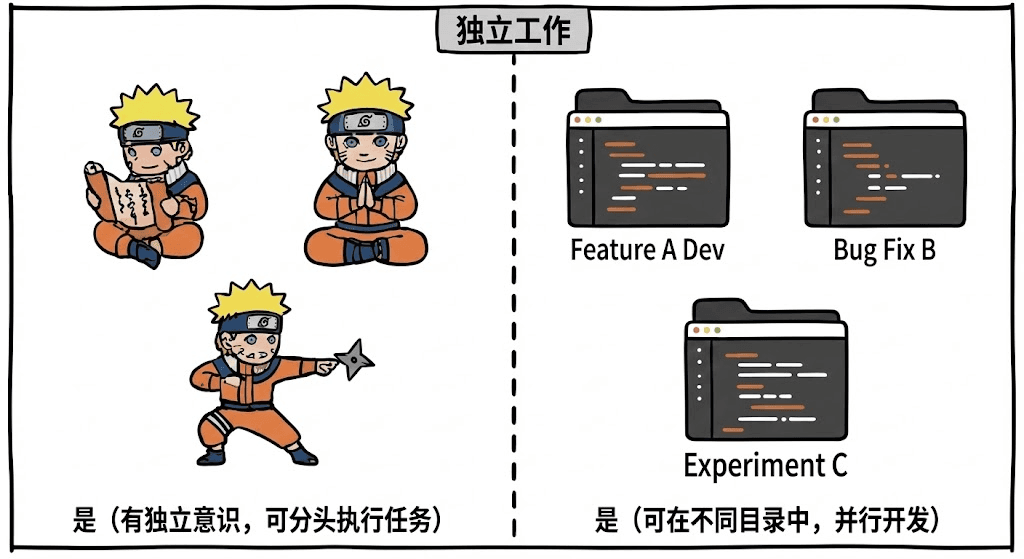
3. 独立行动 = 独立目录
这些分身都能独立行动,他们可以分头侦察、修炼或战斗;
而每个 worktree 也存在于不同的目录里,能各自独立承担一项任务:修 Bug、做实验、新建功能……互不干扰。
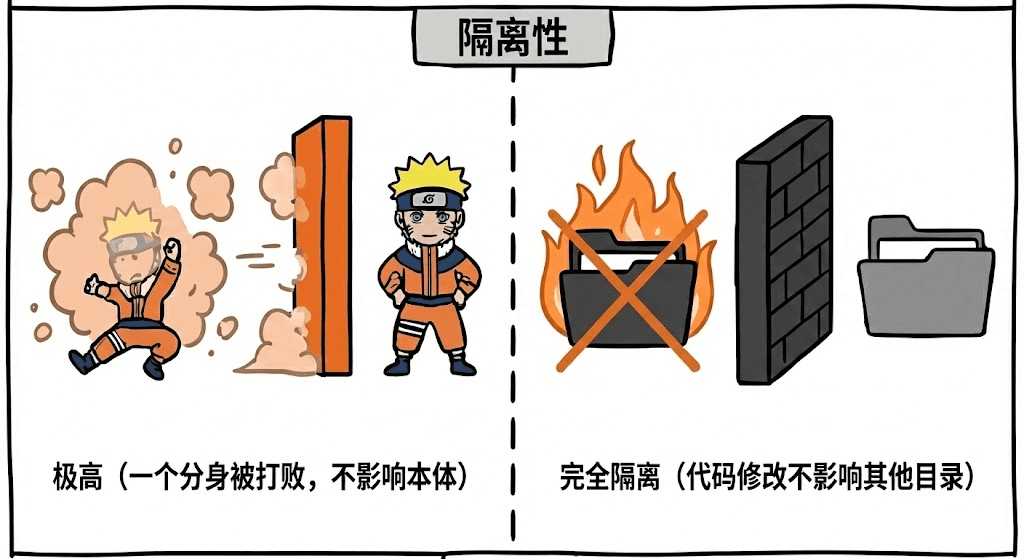
- 分身隔离=代码隔离
隔离性同样强。一个影分身被击败,不会影响本体;
一个 worktree 里的代码怎么切、怎么改,也不会影响其他目录。
5. 经验回流 = Merge
当任务完成后,影分身解除时所有经验会回流到本体;
worktree 也一样,你可以用 git merge 把各个分身的成果合并回主分支,让主仓库获得所有进度。
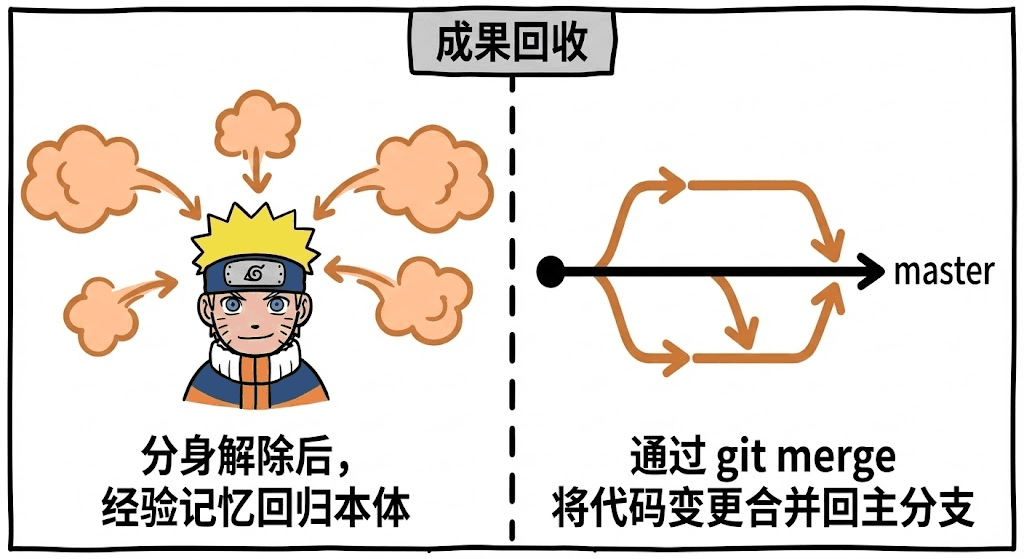
所以,在火影忍者的世界里,影分身是鸣人用来同时修炼、搜集情报、协同战斗的核心技能;
而在软件开发的世界里,Git worktree 则是开发者用来并行开发、紧急修复、多任务代码实验的王牌工具。

实战演练:15 分钟带你“多线战斗”
接下来,还是围绕着为 “Marka” 应用添加“自动配图”功能,我们将使用 Claude Code + Worktree ,尝试同时推进两个新的子任务:
任务 1:让 LLM 自动识别文章里哪些句子适合配图。
任务 2:显示候选图片,手动选择图片插入到文章中。
第 1 步:蓄力(初始化)
首先,请确保你的电脑上已经安装了 Git。 (官网下载:)
在项目根目录下,使用 git init 命令初始化仓库。
git init
这会创建一个 .git 隐藏文件夹,用于追踪所有的版本历史。
许多 IDE(如 VSCode)都内置了 Git 支持,直接点击“初始化仓库”,效果是一样的。
需要注意的是,Git Worktree 是从你当前的 HEAD(可以理解为最新的存档点)检出代码的。如果你手头有改了一半还没存的代码,新的工作目录里是不会有的。
所以,请务必先使用我们前面章节封装好的 /git-commit 命令,,把手头的工作全部提交。
就像鸣人施术前要调整查克拉一样,先确保你的主仓库是完整的,没有未提交的文件。
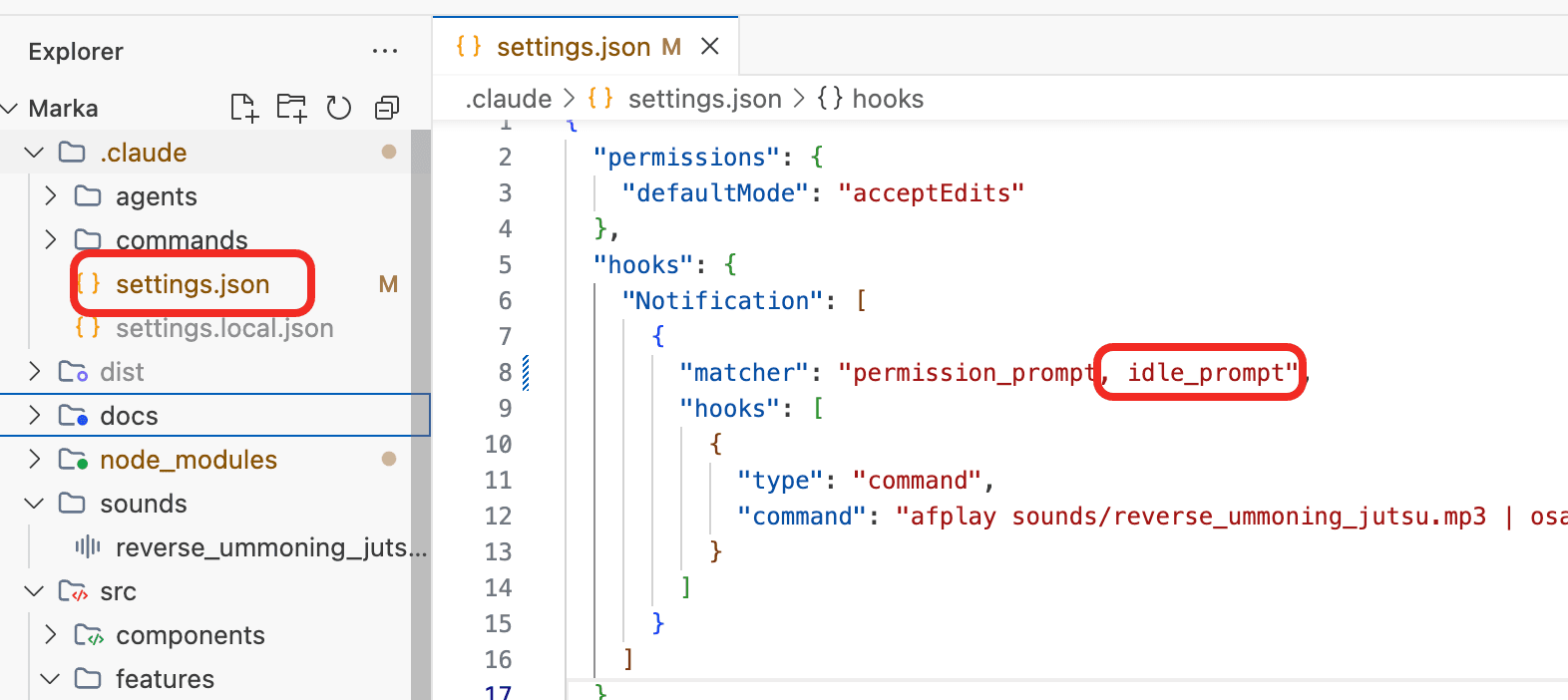
还有一点,还记得我们在前面章节用 Hook 做了一个“防卡死”提示音吗? 如果想让 Claude Code 在任务完成后通知你,可以直接编辑 settings.json 文件,在 matcher 字段增加一个idle_prompt配置。
第 2 步:召唤影分身(创建 worktree)
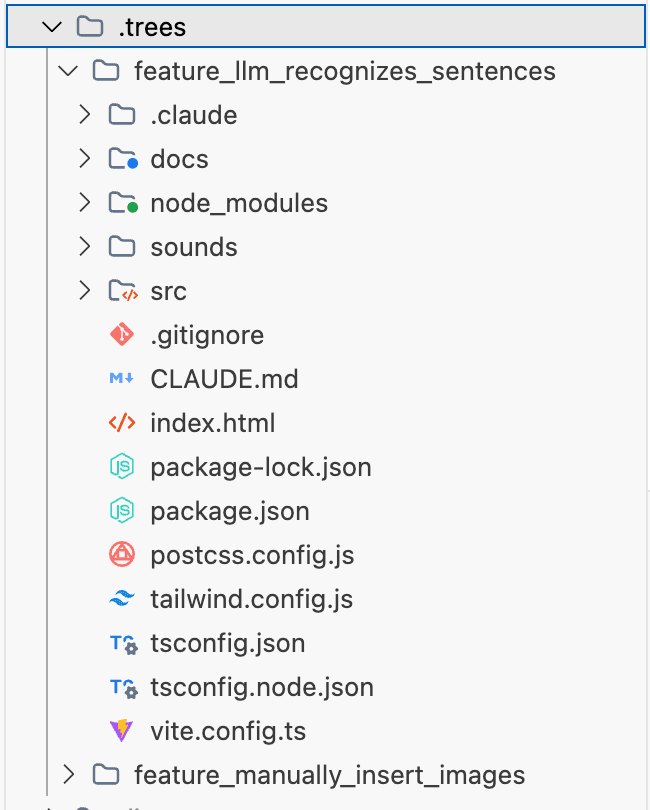
现在,我们要为不同的任务创建专属的工作目录。 为了保持主目录整洁,建议把所有分身都放在一个 .trees 文件夹里。
# 召唤分身 1:LLM识别可配图句子
git worktree add .trees/feature_llm_recognizes_sentences
# 召唤分身 2:手动将图片插入文章
git worktree add .trees/feature_manually_insert_images

就像鸣人结印后产生数个影分身一样,执行过后,你会看到,项目里多了一个 .trees 文件夹,里面躺着两份完整的代码拷贝。
第3步:分头行动(并行开发)
接下来,我们要为每个任务分配一个独立的 Claude Code 实例。
你可以新开两个终端窗口,或直接使用 IDE 的“拆分终端”功能,这样左右并排,更方便观察。
终端 A(左侧):
cd .trees/feature_llm_recognizes_sentences
claude
终端 B(右侧):
cd .trees/feature_manually_insert_images
claude
就像鸣人指挥每个影分身去不同战场一样,你会看到,两个独立的 Claude Code 会话分别在各自的目录中响应。
第4步:战术会商(启用PlanMode)
别急着冲锋。先按下 Shift + Tab 切到“规划模式(Plan Mode)”, 或者使用我们前面章节实现的“提示词优化器” SubAgent。
目的都是为了让 Claude Code 先列出详细的执行计划,而不是上来就改代码。
接下来,分别下达以下指令。不用怕,在规划模式的帮助下,哪怕你的需求描述很糙,Claude Code 也能帮你梳理清楚。
终端 A 输入:
修改API调试窗口,改为将整篇Markdown格式的原文发送LLM,由LLM返回一个JSON列表,每个JSON对象包含“可配图句子”、“可配图理由”、“生图提示词”3个字段,需要校验好JSON格式,确保只返回JSON而没有其他冗余文本,JSON格式不正确的话要发起重试,最多3次。在请求成功之后,遍历所有“可配图句子”,在预览视图中找到对应的句子将其高亮。
终端 B 输入:
在现有的“圆点按钮”组件上增加交互,当鼠标悬停时圆点停止闪烁。鼠标悬停时,一条连接线应从圆点水平延伸并动画显示,最终连接到一个淡入的卡片布局,需要确保卡片布局始终在预览视图,不会溢出。卡片布局内需要横向显示3张候选图片,图片采用正方形容器,缩放显示。点击图片时插入到左侧的Markdown编辑区域,插入位置位于圆点按钮对应句子的句号后面。
Claude Code 可能会主动向你询问一些关键细节,来确保实现方案准确:


澄清完所有问题后,Claude Code 会启动 Plan 代理来设计实现方案,给出 3–10 步的详细计划清单。

就像分身在出征前先各种制定战术、分析敌情,不盲目冲锋一样,
第 5 步:放权执行(开启 Accept Edit )
确认计划无误后,选择 Yes, and auto-accept edits,授权 Claude Code 文件编辑权限,让它能够自动执行。

就像鸣人让分身在战场上自动执行既定战术,而不需要每一招都回头确认一样。
第6步:分身战斗(并行修改)
此时,你会看到两个终端飞速滚动,分别执行各自的任务。

就像分身各自与敌人厮杀,一个硬拼近战,一个潜行远程制敌一样。
由于我们前面设置了提示音,所以我们就不必死盯着屏幕。当听到提示音时,就说明已经完成任务了。

第7步:提交战果(Commit)
在 Claude Code 提示完成任务后,建议先在各自的终端窗口,把项目运行起来验证一下。
如果不符合预期,直接在对应的 Claude Code 会话中继续对话调整。
最后两个任务呈现的结果如下:
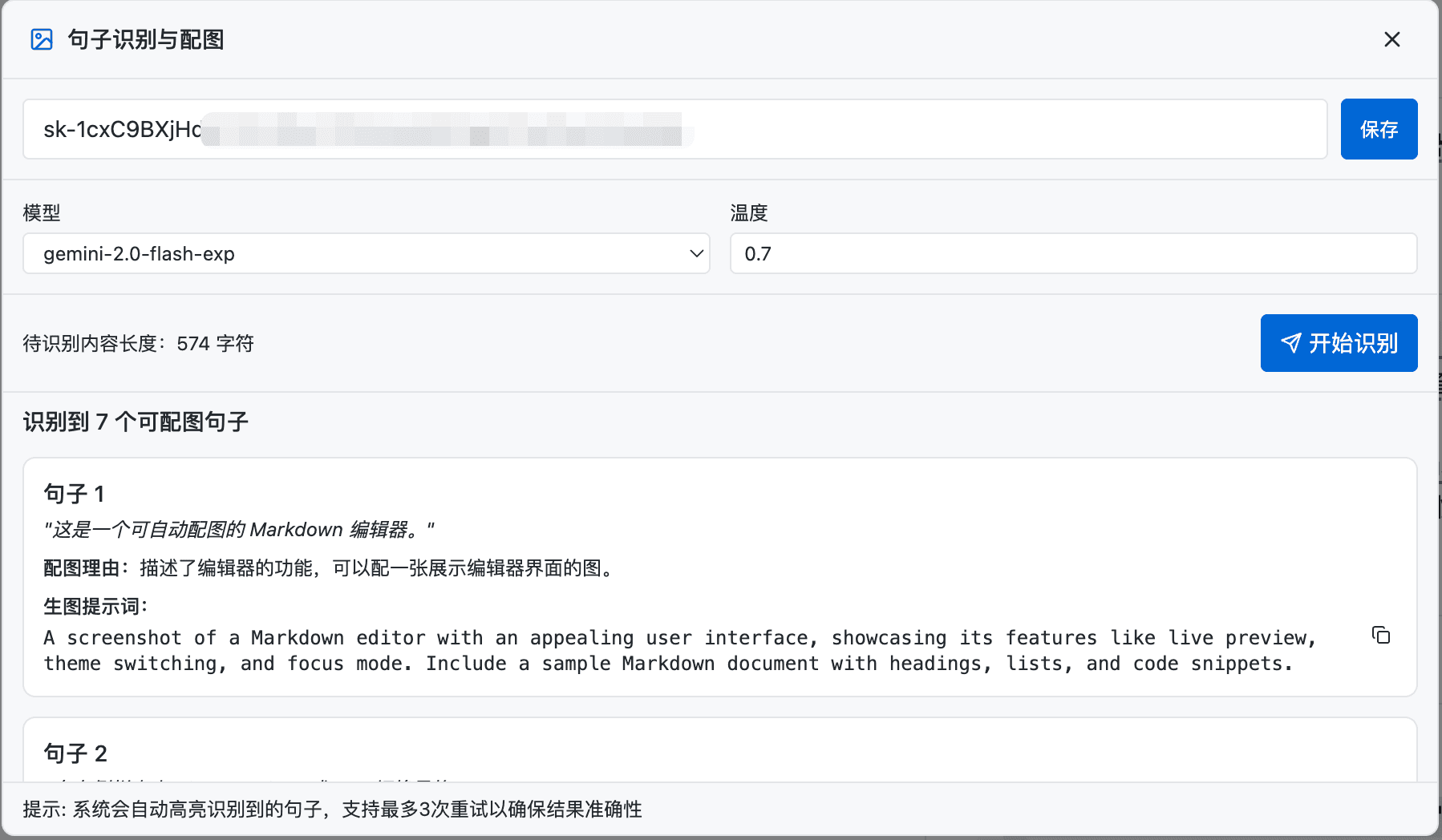
任务 1:LLM 识别可配图句子

任务 2:手动将图片插入文章


确认无误后,我们需要在两个终端里分别执行前面封装的/git-commit命令。

你会看到,两个 Claude Code 实例分别提交了新的代码记录。
就像分身把获取的经验沉淀下来,但这些经验还未回到本体。
第 8 步:经验回流 (Merge)
回到主项目根目录(不要在 .trees 目录下),让 Claude Code 在主会话中,替你合并代码并处理冲突。
"使用 Git Merge 命令合并.tree目录下的所有worktree,并自行处理任何可能的合并冲突。"
你会看到,Claude Code 会自动执行 git merge 操作,将所有独立的开发成果汇集到一起。

如果有冲突,Claude Code 会分析代码逻辑,尝试自动解决(比如保留双方合理的修改)。

最终合并完成,你会看到主分支拥有了“LLM 识别”和“手动插图”两个功能的所有代码。

就像分身解除,所有分身的经验(commit)被回传给本体,鸣人学习了各分身在战场上的所得一样。
给读者的建议
最后,关于使用 Git Worktree 并行开发,我有几条建议想送给你:
CPU 调度思维: Worktree 的核心价值在于打破线性等待。当左边窗口的 Claude Code 正在写代码时,你应该立刻去右边窗口规划新任务。学会像 CPU 调度线程一样调度你的 Claude Code,填满所有等待的空隙。
大胆试错: 别指望自己能小心翼翼不改错文件。Worktree 提供了物理隔离的沙盒,这让你在修改代码时心理负担降为零。既然影响不到主分支,那就大刀阔斧地去试错吧。
阅后即焚,保持清爽: 影分身用完是要解除的。任务合并完成后,那些临时目录就成了废纸。养成随手清理的好习惯,不要让临时分身变成硬盘里的“僵尸”。