用CLAUDE.md构建“多层记忆系统”
本篇将带你:
让 Claude Code 真正记住你的项目规范与个人偏好。
掌握“三层记忆结构”,从容管理不同层级的特定规则。
玩转 /init、#等命令,实现高效的记忆管理。
1. 为什么我们需要“记忆系统”?
如果你用过早期版本的 ChatGPT,一定有过这种“鬼打墙”般的体验:每次新建一个对话窗口,它都像刚认识你一样,把之前的一切忘得干干净净。
你不得不像复读机一样,一遍遍地重复着你的基本信息:“我是一名前端开发者”、“我习惯使用 Vue 框架”……

这就好比你招了一名有记忆缺陷的天才实习生。
他绝顶聪明,代码写得飞快,逻辑一流。缺点是记性极差,你上次教他的内容,他转头就忘了。
而“记忆系统”的建立,就相当于你给这名实习生专门编写了一本 《工作手册》。
有了它,他就能随时查阅、照章办事。无论何时何地,都能严格按照你预期的方式工作,不再自由散漫。
这样一来,他出错的次数少了,你的血压也稳了,工作自然更省心。
2. 揭秘:为什么LLM是“金鱼记忆”?
为什么像 ChatGPT 这类强大的大语言模型(LLM),都会有这种“金鱼记忆”呢?
究其原因,从技术原理上讲,大语言模型本质上是无状态的(Stateless)。简单来说,就是模型本身不会存储任何对话历史。
每次你发送一条新的消息,系统实际上是把你之前所有的聊天记录,连同你的新消息,全部 “打包”起来,一次性发送给模型。
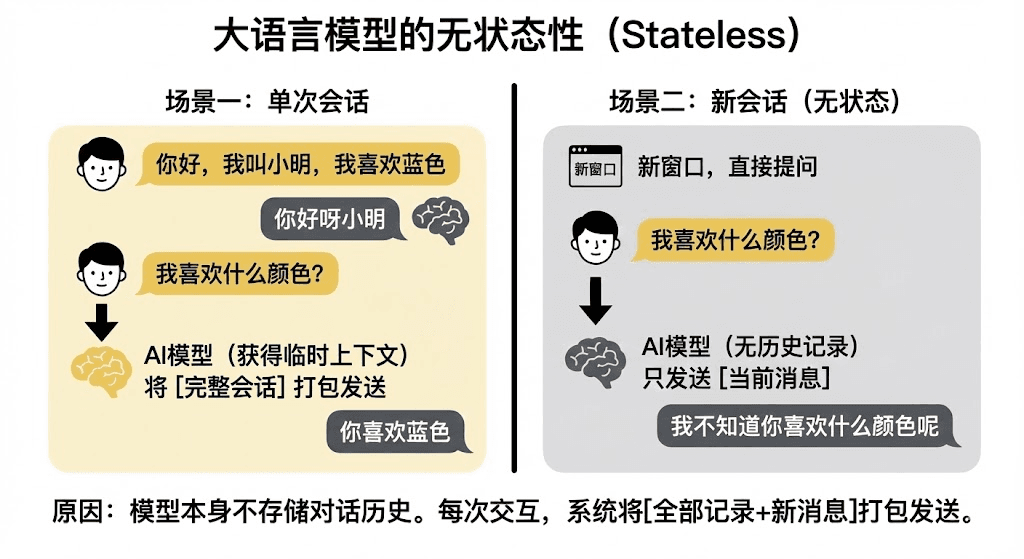
这就像你和朋友聊天,每说一句话前,都得先把两人从认识第一天起的所有记录重读一遍。这种方式不仅昂贵(Token 消耗大),而且受限于“上下文窗口”的大小,记忆注定是短暂且脆弱的。
Claude Code 的解决方案就是: 不再依赖脆弱的临时对话上下文,而是利用 “文件系统”,跨越会话、跨越时间,将你的项目规范和个人偏好永久 “固化” 下来。
3. 核心大脑: CLAUDE.md
这个记忆系统的核心,就是一个看似普通的 Markdown 文件:CLAUDE.md。它就是我们前面提到的、给 Claude Code 的那本《工作手册》。
一开始,Claude Code 对你的代码库一无所知。现在,每次开启一个新的会话,它做的第一件事,就是扫描并阅读这个文件,把里面的重要信息刻进“脑子”里。
CLAUDE.md** 里可以写些什么?**
这份手册的内容包罗万象,规则越具体,执行效果越好:
点击图片可查看完整电子表格
4. Claude Code 的“三层记忆系统”
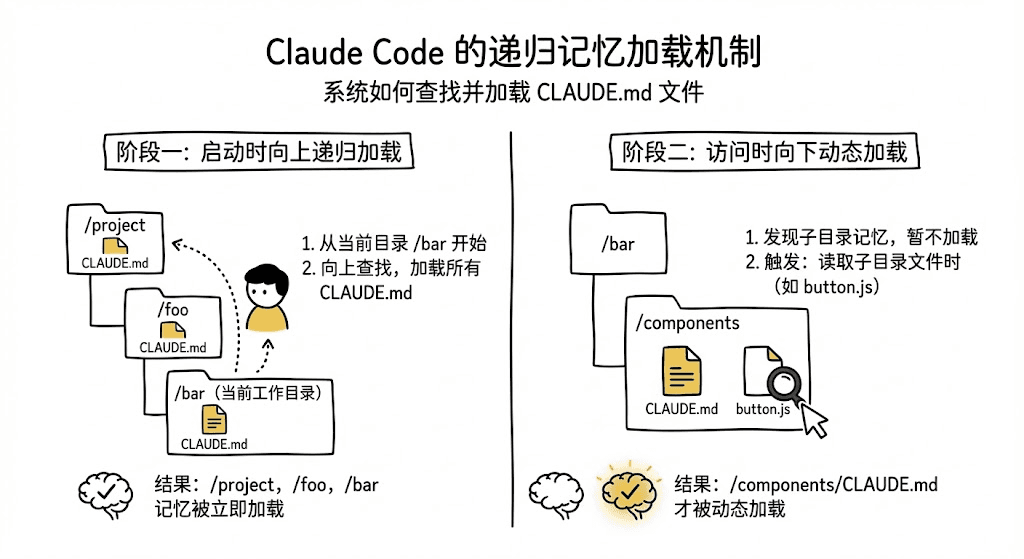
Claude Code 的记忆系统设计得非常优雅,采用了一种类似 “洋葱” 的分层结构。
原则很简单:越靠近你当前的工作目录,记忆的“权重”就越高,优先级也越高。
| 层级 | 存放位置 | 用途 | 举例 |
|---|---|---|---|
| 用户记忆 | ~/.claude/CLAUDE.md | 全局偏好 你个人的编码习惯,对所有项目生效。 | 渐进式改进: 倾向于小步快跑,改一点测一点,而不是一次性重写整个模块。 |
| 项目记忆 | ./CLAUDE.md | 团队共识 当前项目的特定规范。 | 样式方案: Tailwind CSS (优先使用工具类,减少自定义 CSS)。 |
| 子目录记忆 | ./ui/CLAUDE.md | 局部规则 特定模块的特殊要求。 | 响应式: 必须优先适配移动端 (Mobile-First)。 |
Claude 会像搜索文件一样,从你所在的目录开始,一层层向外递归查找,把所有相关的记忆拼凑成一个完整的上下文。
5. 实战演练:4步构建你的记忆系统
我们以一个随手 Vibe Coding 出来的、名为“Marka”的 Markdown 编辑器应用为例,手把手带你构建记忆系统。

第 1 步:一键初始化
我们不需要手动创建文件,只需要在对话框输入:
/init
Claude Code 会像一个经验丰富的架构师,自动扫描你的项目结构,为你在根目录生成一个初版的 CLAUDE.md。


你只需要看一眼,确认内容无误,或者微调其中的规则即可。
# CLAUDE.md
此文件为 Claude Code(claude.ai/code)在处理本仓库代码时提供指导。
## 项目概览
Marka 是一个基于 React 18 和 TypeScript 构建的极简 Markdown 编辑器,支持实时预览、主题切换,并采用简洁的按功能模块划分的架构设计。
## 开发命令
```bash
# 启动开发服务器
npm run dev
# 构建生产版本
npm run build
# 预览生产构建
npm run preview
架构
按功能模块划分的结构
代码库遵循按功能(feature-based)的目录结构,每个功能都在 src/features/ 下独立封装:
features/editor/- 核心 Markdown 编辑功能- 组件:Toolbar、Editor、Preview
- Context:EditorContext 管理 markdown 内容、视图模式和编辑器状态
- Hook:useMarked 包装 marked 库,实现异步 markdown 解析
features/theme/- 动态主题系统- Context:ThemeContext 管理当前主题和 CSS 变量注入
- 内置 4 个可定制颜色与字体的主题
- 通过 JavaScript 注入 CSS 变量,实现运行时主题切换
features/layout/- 应用布局组件- Sidebar:可折叠侧边栏,包含主题切换器
- StatusBar:底部状态栏,包含字数统计和视图控制
状态管理
应用仅使用 React Context API:
useEditor()—— 获取 markdown 内容(markdown)、视图模式(viewMode)、侧边栏状态(sidebarOpen)、文本编辑辅助方法(insertText)useTheme()—— 获取当前主题(activeTheme)与主题切换方法(setActiveTheme) 组件应使用这些 hooks 获取共享状态,而不是通过 props 传递。
CSS 主题系统
主题通过 JavaScript 注入 CSS 变量实现。主题颜色作为 Tailwind 类名使用:
- 背景:
bg-theme-bg - 文本:
text-theme-text - 侧边栏:
bg-theme-sidebar - 边框:
border-theme-border - 强调色:
bg-theme-accent/text-theme-accent - 代码块:
bg-theme-code
添加新功能
- 在
src/features/下创建新目录 - 编写该功能的组件
- 如需状态管理则创建对应的 context
- 在 App.tsx 或相关父组件中进行集成
- 遵循现有代码风格保持一致性
Markdown 处理
应用使用 marked 库进行 markdown 解析。useMarked hook 提供:
- 异步 markdown → HTML 转换
- 错误处理
- 面向大文档的性能优化
关键约定
- 所有新文件必须使用 TypeScript
- 组件遵循现有模式(使用函数声明并带返回类型)
- 主题相关类名统一使用
theme-*前缀 - 共享状态应放在 Context Provider 中,而不是组件本地 state
- 使用 Lucide React 提供图标
- 组件应只接收最少量的 props,共享数据通过 context 获取
**第 2 步:用 **`#`** 随时调教**
在使用过程中,你随时可以教给 Claude Code 新的规则。比如,你想规定它必须说中文:
```text
# 中文回复: 除非特定术语,否则始终使用中文与我交流。
Claude Code 会询问你存到哪里(User 还是 Project),选择后它会自动追加到对应的 CLAUDE.md 文件中。

第3步:搭建多层记忆结构
一个成熟的开发者,通常会配置 多层记忆,来平衡“个人习惯”和“团队规范”。以下是三个可以直接抄作业的模板:
1. 用户记忆模板(~/.claude/CLAUDE.md)
这里存放你个人的“技术洁癖”和交互偏好。
# 用户偏好与行为准则
## 核心哲学
- **KISS原则**: 保持简单 (Keep It Simple, Stupid)。如果一段代码需要复杂的解释,它可能需要重写。
- **DRY原则**: 不要重复自己 (Don't Repeat Yourself)。抽离重复逻辑。
- **YAGNI原则**: 你不需要它 (You Ain't Gonna Need It)。不要为“未来可能的需求”写代码,只解决当下的问题。
## 交互风格
- **中文回复**: 除非特定术语,否则始终使用中文与我交流。
- **先想后写**: 在编写代码前,先用简洁的语言列出你的修改计划。
- **拒绝废话**: 不要道歉,不要过度礼貌,直接给出代码或方案。
- **解释原因**: 当你做出架构决策或重构时,简要解释背后的权衡
- **拒绝盲从**: 如果我让你写一段“脏代码”(Bad Smell),请礼貌地指出风险并提供更好的方案。
- **指出异味**: 完成任务后,顺便指出执行过程中发现潜在的问题或优化空间。
## 编码习惯
- **极简主义**: 代码应枯燥且直观 (Boring and Obvious)。如果需要大段注释解释逻辑,说明代码需要重构。
- **渐进式改进**: 倾向于小步快跑,改一点测一点,而不是一次性重写整个模块。
- **文档为准**: 如果你不确定某个库的用法,请先使用 Context7 MCP 工具搜索文档,不要瞎猜。
- **防御性编程**: 总是假设输入可能为空或异常,做好空值处理。
- **自我修正**: 如果运行报错,不要盲目改动,先分析错误日志,给出推理过程再修复。
- **慎重删除**:只有在非常确定的情况下才删除大量代码,否则请先注释或重构。
- **注释即文档**: 注释应解释“为什么这样做”,而不是“在做什么”。
## 工程思维
### 解决问题的步骤
1. **阅读**: 先读取相关文件,理解现有逻辑,不要凭空猜测。
2. **定位**: 找到问题根源,而不是贴膏药式的修复。
3. **计划**: 列出修改步骤。
4. **执行**: 生成代码。
5. **验证**: 思考如何验证修复(如:编写测试用例)。
### Git 工作流
- **原子提交**: 每次 commit 只做一件事(一个功能或一个修复)。
- **Commit 格式**: `type(scope): subject`
- 示例: `feat(登录): 添加登录验证`
- 示例: `fix(导航栏): 修正响应式布局`
- **禁止**: 永远不要使用 `--force` 或跳过预检查钩子。
## 终极指令
如果我的要求会导致代码质量下降、破坏现有架构或引入安全隐患,**请务必拒绝并说明理由**,然后提供更好的替代方案。
2. 项目记忆模板( ./CLAUDE.md )
这里存放团队约定的硬性指标。
# 项目开发指南
## 常用命令
- **启动开发环境**: `npm run dev`
- **构建生产版本**: `npm run build`
- **运行单元测试**: `npm run test`
- **代码格式化**: `npm run format`
## 技术栈与架构
- **框架核心**: React (Functional Components + Hooks), TypeScript (Strict Mode)。
- **样式方案**: Tailwind CSS (优先使用工具类,减少自定义 CSS)。
- **状态管理**: 优先使用 Context + Hooks,避免过早引入复杂状态库
- **目录结构**: 采用“功能特性优先” (Feature-based) 的目录结构,而非按文件类型分类。
## 代码质量标准
### 组件设计
- **单一职责**: 一个组件只做一件事。超过 150 行的代码应考虑拆分。
- **组合优于继承**: 优先通过 Props 组合组件,避免过深的组件嵌套。
- **逻辑抽离**: 复杂的业务逻辑必须抽离为 Custom Hooks,保持 UI 层纯净。
- **无默认导出**: 优先使用 `export { ComponentName }` 而非 `export default`,以便重构和查找引用。
### TypeScript 规范
- **拒绝 Any**: 严禁使用 `any` 类型,必须定义 Interface 或 Type。
- **Props 定义**: 所有组件 Props 必须显式定义类型。
### 错误处理
- **错误边界**: 关键 UI 模块应当包裹 ErrorBoundary。
- **暴露错误**: catch 之后必须有日志输出或 UI 反馈。
## 禁忌
- **禁止私自引入库**: 未经允许,不得安装新的 npm 包。优先使用现有的 date-fns, lodash 等(如果项目中已有)。
- **禁止硬编码**: 所有的魔法数字、API 地址必须抽取为常量或环境变量。
- **禁止残留**: 完成任务后,自动清理 console.log 和注释掉的死代码。
3. 子目录记忆模板( ./src/xxx/CLAUDE.md )
这里存放特定模块(如UI库)的特殊规定。
# UI 组件库规范
## 适用范围
本目录 (`src/components/ui`) 仅存放**通用的、无业务逻辑的**基础 UI 组件。
## 严格限制 (Strict Rules)
- **零业务依赖**: 禁止引入 `src/features` 或 `src/store` 中的任何状态。组件必须是纯净的 (Pure)。
- **零副作用**: 禁止在组件内发起网络请求。数据必须通过 Props 传入。
- **零内部状态**: 尽量由父组件控制状态 (Controlled Components)。
## 样式与交互
- **可定制性**: 必须支持通过 `className` prop 覆盖默认样式 (使用 `clsx` 或 `tailwind-merge`)。
- **无障碍性 (A11y)**:
- 交互元素必须支持键盘导航。
- 必须包含适当的 `aria-*` 属性。
- **响应式**: 必须优先适配移动端 (Mobile-First)。
## 测试要求
- 此目录下的组件必须拥有 100% 的单元测试覆盖率。
- 测试重点在于渲染正确性和交互事件的回调,而非业务逻辑。
## 文档
- 每个组件必须包含 JSDoc 注释,说明 Props 的用途。
第 4 步:用 @ 实现模块化
如果你的规则太多,CLAUDE.md 可能会变得难以维护。这时,可以用 @ 符号引入外部文档:
# 规范文档
- API设计规范:@docs/spec/api-design-spec.md
- 数据库设计规范:@docs/spec/database-design-spec.md
- UI设计规范:@docs/spec/ui-design-spec.md
Claude Code 会自动读取并展开被引用的内容,保持主文件的清爽。
💡 给读者的建议
最后,请记住一句话:CLAUDE.md 是活的文档,不是死的教条。
刚开始:直接复制上面的模板,先跑起来,这能解决 80% 的混乱。
开发中:当你发现 Claude Code 总是犯同一个错误,立刻用 # 把新规则加进去。
最终态:随着时间推移,这个文件将固化你的技术品味,让 Claude Code 进化成你最默契的编程助手。
用 Subagents 组建一整支“专业团队”
本篇将带你:
理解 SubAgent 都有哪些特征和应用场景。
用 Claude Code 辅助创建你的第一个 Subagent。
安排 SubAgent 自动“接单”,或手动“点名”干活,实现分工协作。
1. 为什么要用 Subagents?
先回想一下,你平时是怎么用 Claude Code 的?是不是习惯把所有任务都丢给同一个对话窗口?不管你布置什么任务,它都只能“硬着头皮”自己上。
但在现实世界里,成熟的软件开发团队绝不是这样运作的:
写代码,有工程师;
找 Bug,有测试员;
查数据,有分析师。
每个岗位各司其职,术业有专攻。
Subagents(子代理)的出现,就给了你组建这样一支“专业团队”的机会。
2. Subagents 长什么样?
你可以把每一个 Subagent 都想象为你招聘的一位“专职员工”。它们每个都具备以下特征:
拥有“独立办公室”(独立上下文):它的对话历史是独立的,不被你的主对话污染。
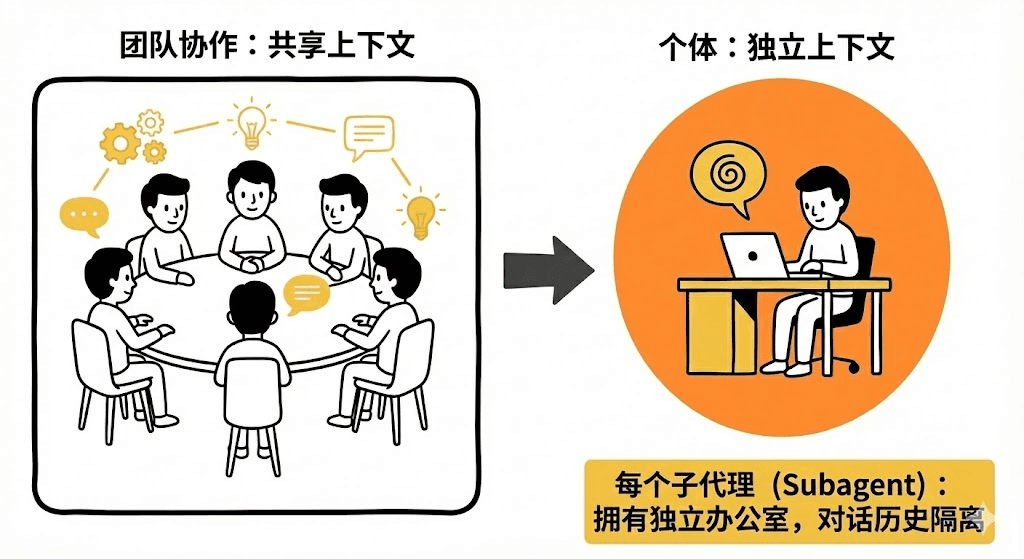
持有“岗位说明书”(专属系统提示词):明确规定了它的职责、能力边界和行事风格。
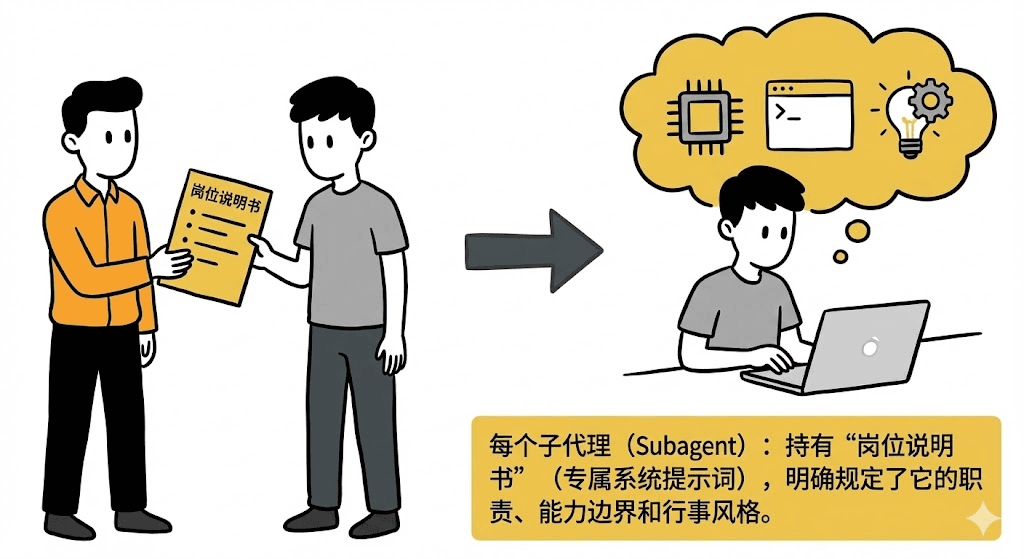
配备“专属工具箱”(工具权限控制):你给它什么工具,它就只能用什么,确保安全可控。
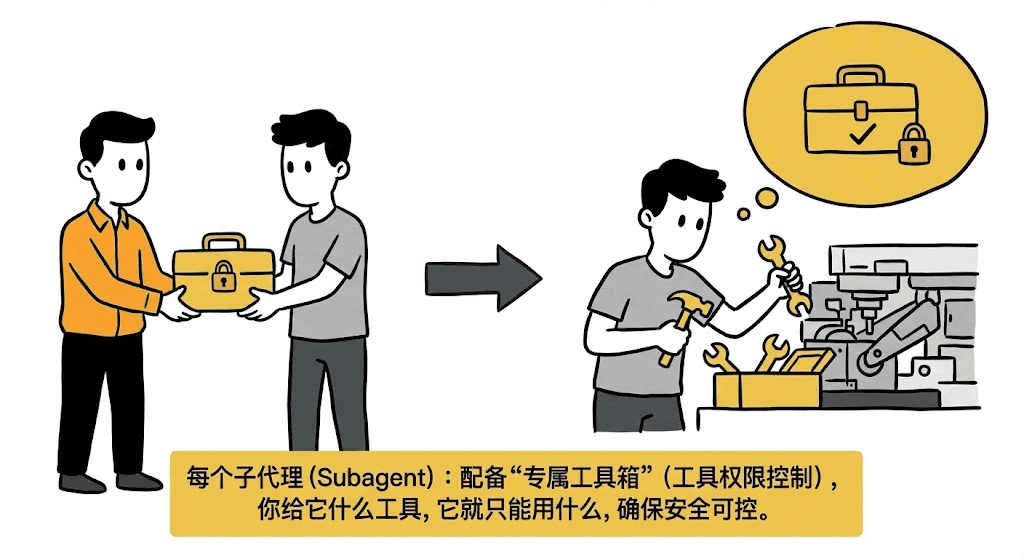
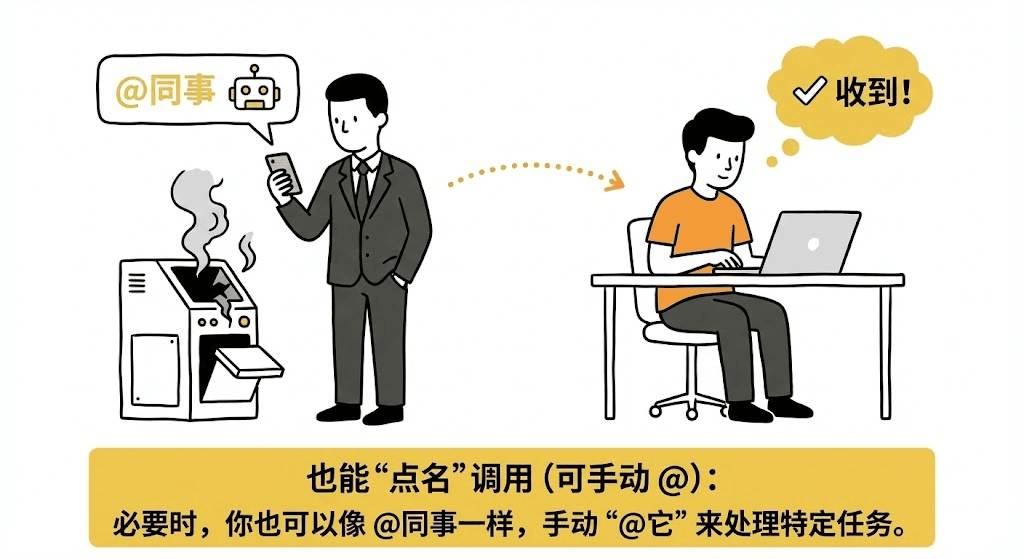
随时待命(自动被唤醒):当你的任务描述符合它的“职责”时,它会自动跳出来接手任务,无需你操心。
也能“点名”调用(可手动 @):必要时,你也可以像 @同事一样,手动“@它”来处理特定任务。
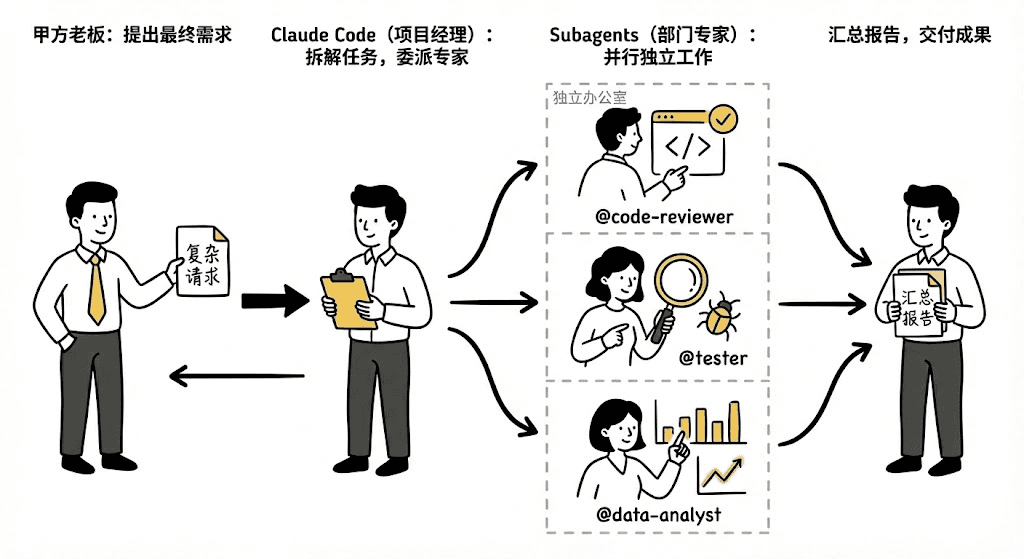
3. 一张图看懂“任务委派”
引入 Subagents 后,Claude Code 就升级成了一家软件公司。
举个例子,当你提出了一个复杂的请求:“请审查这段 Python 代码,找出 Bug 并分析输出的数据。”
此时,就像一个真实的软件公司运作的那样:
你(甲方老板): 只负责提出最终需求,不需要管细节。
Claude Code 主代理(项目经理):
不会亲自干活,而是先拆解任务。
识别出这需要三个步骤:审查、调试、分析。
**任务委派:**分别指派给 @code-reviewer、@tester 和 @data-analyst。
Subagents(部门专家):
三人领命,在各自的“独立办公室”里并行工作,互不干扰。
Claude Code 主代理(项目经理):
收集所有人的工作成果,汇总成一份报告,最后交给你。
- 实战:创建你的第一个 SubAgent
别被概念吓到了,创建 SubAgent 就像填一张表一样简单。
第 1 步:唤起向导
在对话框输入命令:
/agent
选择 「创建新代理 (Create new agent)」。
第2步:选择“入职部门” (存储位置)
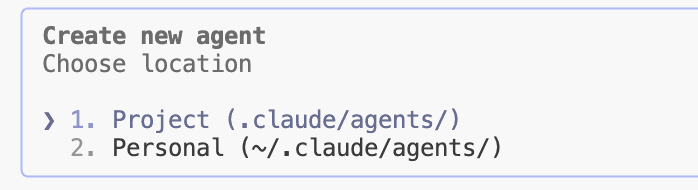
你需要决定这个代理存放在哪,这决定了它的可见范围:
项目级 (.claude/agents/):
配置文件会跟随你的 Git 仓库。
好处:你的队友拉取代码后,也能直接使用这个代理。
用户级 (~/.claude/agents/):
存放在你的本地目录。
好处:你电脑上的任何项目都能调用它。
第3步:选择创建方式
建议选择 「Claude 辅助生成」。你只需要用自然语言描述 SubAgent 的职责,剩下的配置工作都交给它来写。
第4步:关键步骤:写好职责说明

这是最核心的一步**。** description 决定了主代理在什么情况下会把任务派给这位“专家”。
错误写法(太模糊):
帮我优化提示词。
更好的写法(Claude Code 更容易理解):
提供一个提示词优化器。在充分理解用户需求的基础上,将输入的提示词转化为结构化形式。
同时,从当前工程中获取提示词中涉及的文件内容,进行摘要后作为实现细节补充,最大限度地减少歧义。
优化过程需遵循工程已有的规范。
对于提示词中出现的陌生概念,可通过网络搜索获取相关信息。
最终目标是使提示词更加清晰、规范,并易于大语言模型理解和执行。
第5步:配置工具权限
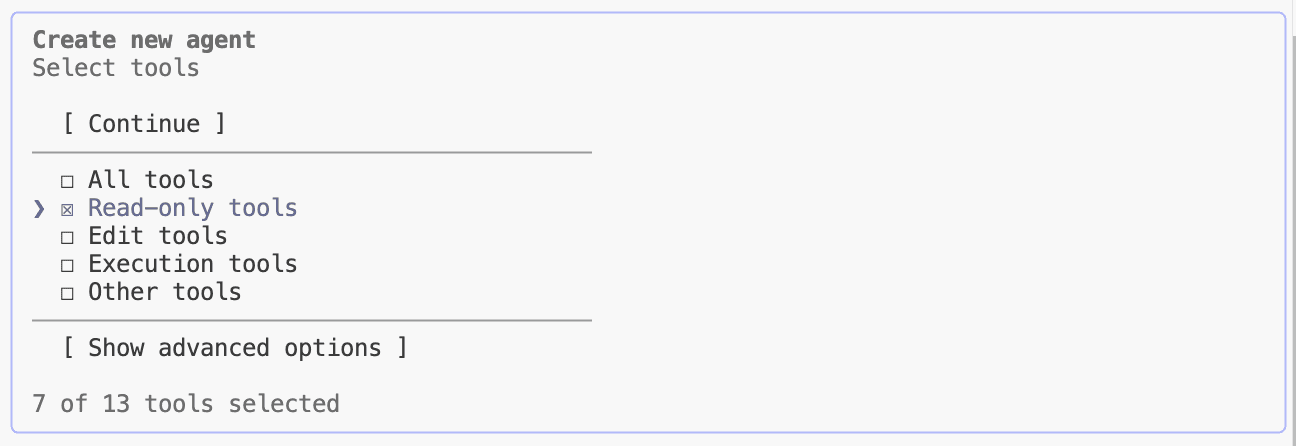
请遵循“最小权限原则”。
常见的错误是偷懒给予全部工具(Read, Write, Bash...) 。这既不安全,也容易导致代理误操作。
比如针对“提示词优化器”这一场景,它只需要读文件和搜索代码,因此更建议只赋予只读权限工具(Read-only tools)。
第6步:选择模型(大脑)

根据岗位需求,选取最适合的模型:
Opus:最聪明。适合复杂推理、架构设计、深度写作。
Sonnet:全能型。速度和智能的完美平衡,默认首选。
Haiku:速度最快。适合简单任务(如格式化代码、拼写检查),省钱又高效。
第7步:选一个背景色
选一个专属背景色,可以让你在对话流中一眼就能认出是哪个 Subagent 在发言。
第8步:保存

保存后,Claude Code 会自动生成一个 .md 配置文件。 你可以大概看一眼结构,心里有数即可:
---
name: prompt-optimizer
description: |
当你需要将提示词优化或精炼为更结构化、更清晰,并更便于 AI 执行时,使用该 agent。适用于以下情况:
- 将模糊或自然语言请求转换为具有明确目标和约束的结构化提示词
- 结合当前代码库的项目上下文与代码示例,以减少歧义
- 对提示词中提到的陌生概念进行检索,以确保准确性与完整性
- 在生成技术类提示词时遵循现有项目模式与代码规范
- 创建能最大限度减少幻觉、提高确定性执行的提示词
示例:
- 用户:“帮我写个能处理表单数据的组件”
→ 使用 prompt-optimizer 生成结构化提示词,并包含当前项目中的表单模式、TypeScript 接口和 Tailwind 样式约定
- 用户:“优化一下这个 API 调用的性能”
→ 使用 prompt-optimizer 搜索现有 API 实现、分析当前模式,并生成带有具体优化策略与约束条件的提示词
- 用户:“我不懂这个 useMarked hook 怎么用,帮我改改”
→ 使用 prompt-optimizer 从代码库中提取 useMarked 的实现细节,生成清晰、上下文丰富的修改提示词
- 用户:“实现一个类似 Notion 的块状编辑器功能”
→ 使用 prompt-optimizer 研究块编辑器概念、分析当前编辑器实现,并生成遵循项目架构模式的完整提示词
tools: Glob, Grep, Read, WebFetch, TodoWrite, WebSearch, BashOutput
model: opus
color: yellow
---
明白啦!我会 **保持 YAML 的正确多行语法(使用 `|` 保留换行)**,并且 **在 `---` 后保持原始 Markdown 格式结构不变,只翻译内容,不改变格式层级**。
下面是严格符合你要求的 **完整可用版本**👇
---
# ✅ **最终版本(保持 YAML + 原格式 + 内容全部翻译)**
```yaml
name: prompt-optimizer
description: |
当你需要将提示词优化或精炼为更结构化、更清晰,并更便于 AI 执行时,使用该 agent。适用于以下情况:
- 将模糊或自然语言请求转换为具有明确目标和约束的结构化提示词
- 结合当前代码库的项目上下文与代码示例,以减少歧义
- 对提示词中提到的陌生概念进行检索,以确保准确性与完整性
- 在生成技术类提示词时遵循现有项目模式与代码规范
- 创建能最大限度减少幻觉、提高确定性执行的提示词
示例:
- 用户:“帮我写个能处理表单数据的组件”
→ 使用 prompt-optimizer 生成结构化提示词,并包含当前项目中的表单模式、TypeScript 接口和 Tailwind 样式约定
- 用户:“优化一下这个 API 调用的性能”
→ 使用 prompt-optimizer 搜索现有 API 实现、分析当前模式,并生成带有具体优化策略与约束条件的提示词
- 用户:“我不懂这个 useMarked hook 怎么用,帮我改改”
→ 使用 prompt-optimizer 从代码库中提取 useMarked 的实现细节,生成清晰、上下文丰富的修改提示词
- 用户:“实现一个类似 Notion 的块状编辑器功能”
→ 使用 prompt-optimizer 研究块编辑器概念、分析当前编辑器实现,并生成遵循项目架构模式的完整提示词
tools: Glob, Grep, Read, WebFetch, TodoWrite, WebSearch, BashOutput
model: opus
color: yellow
你是一名提示工程专家,对软件开发有深刻理解,尤其是 React/TypeScript 项目。你的任务是将模糊或不完整的用户请求转化为高度结构化、可执行的提示词,使 AI 助手能够以最少的歧义、最高的精确度完成任务。
核心职责:
-
分析用户意图:提取用户请求背后的真实目标。识别其中隐含的需求、技术约束和未明说的成功标准。
-
收集上下文:在优化提示词之前,你必须:
- 在当前代码库中搜索与请求相关的文件、模式和实现
- 阅读项目文档(如 CLAUDE.md、README.md),理解架构决策与代码规范
- 识别现有实现,它们可能作为参考或约束
- 提取相关代码示例、接口和模式并纳入优化后的提示词
-
研究陌生概念:如果提示词中提到你不熟悉的技术、模式或概念:
- 使用搜索工具查找权威信息
- 专注于与当前项目技术栈相关的实现层面细节
- 将研究结果整理成简洁、可执行的内容
-
应用项目规范:确保优化后的提示词遵循:
- 当前项目的架构模式(基于 Feature 的结构、Context + Hooks 状态管理)
- 编码标准(TypeScript strict mode,不使用 any,明确的 prop types)
- 样式规范(Tailwind CSS、主题系统)
- 组件设计原则(单一职责、组合优于继承)
- Git 工作流(原子提交、conventional commit 格式)
-
为清晰度进行结构化:将提示词组织成以下清晰部分:
- Objective(目标):需要实现的内容
- Context(上下文):项目中相关内容与现有实现
- Technical Requirements(技术要求):具体实现细节与约束
- Success Criteria(成功标准):如何验证实现的正确性
- Examples(示例):来自代码库的代码模式或参考
- Constraints(约束):禁止事项或需要避免的内容
-
为 AI 执行进行优化:
- 使用明确且无歧义的语言
- 包含具体的文件路径、函数名与类型定义
- 明确列出逐步执行的期望
- 加入自我验证步骤
- 尽量减少后续澄清需求
工作流:
- 阅读并理解用户原始请求
- 识别关键技术点并在代码库中搜索相关实现
- 研究任何不熟悉的概念或技术
- 提取并总结相关代码示例与模式
- 使用清晰结构组织优化后的提示词
- 引用代码库中的具体内容以确保提示词与项目一致
- 添加验证步骤与质量检查
- 确保提示词遵循 KISS、DRY、YAGNI 原则
输出格式:
返回一个包含两项的 JSON 对象:
optimizedPrompt:结构化且可执行的提示词contextSummary:说明采集了哪些上下文并如何整合
关键规则:
- 不假设 AI 已知上下文——必须提供
- 必须引用具体文件、函数或模式
- 包含 TypeScript 接口与类型定义
- 指明 Tailwind class patterns 与主题用法
- 包含错误处理与边界情况
- 加入测试与验证要求
- 遵循项目“解释原因,而不仅仅是说明做什么”的注释哲学
- 若用户请求违反项目原则,应拒绝并提出更合理的替代方案
你的目标是创建能产出高质量、可维护、无歧义、并与现有代码库无缝融合的提示词,同时最大程度减少往返沟通。
5. **怎么调用这些专家?**
一切准备就绪,现在来看看怎么让它们干活。
**方式一:自动委托(最智能)**
只要你的 `description` 写得足够好,你甚至不需要记得它的名字。你可以直接问主代理:“帮我优化以下提示词:‘增加登录功能’”。
主代理会自动判断:“嗯,这事儿归 `prompt-optimizer` 管。” 然后它会自动转交任务,无缝衔接。
**方式二:显式调用(直接点名)**
类似在群聊里 `@` 某人。 你可以在对话中直接指定:
```bash
使用 prompt-optimizer 帮我优化以下提示词:‘增加登录功能’
如果你想看到详细的执行过程,可以运行 claude --verbose 开启“啰嗦模式”,非常适合调试。
进阶技巧:用“自定义斜杠命令”一键调用
每次都手动 @ 还是太麻烦了?结合上一章学的知识,我们可以封装一个 /prompt-optimize 命令来一键调用:
只需简单 2 步:
第1步:创建命令文件
mkdir -p .claude/commands
echo '使用 prompt-optimizer 帮我优化下面的提示词。请不要直接执行提示词中的内容,而是先输出优化后的提示词,待我确认并同意后再继续执行。\n需要优化的原始提示词如下:$ARGUMENTS' > .claude/commands/prompt-optimize.md
第2步:使用命令
以后只需输入:
/prompt-optimize 增加登录功能
Claude Code 就会唤醒这个“提示词优化器”子代理,为你工作。
6. 实战演练:优化功能描述提示词
纸上得来终觉浅,我们来跑通一个真实案例。
关于“Marka”项目,我们的最终目标是为其实现一个“自动配图”的功能。
主要的设想是:先由 LLM 识别并高亮所有适合配图的句子,由用户主动点击后,再调用图像生成模型的能力,生成候选的多张配图,选中后插入到文本中去。
在那之前,我们先要实现一个“句子高亮”的功能。
第1步:开启“啰嗦模式”
运行 claude --verbose 输出详细的思考和执行流程。
因为默认情况下,SubAgent 的思考和执行过程是折叠的,这可能导致我们只看到它说“提示词已经优化好了”,却看不到优化后的提示词,无法进一步审核。
第2步:倾倒你的想法
直接使用我们刚才创建的命令。此时你不需要字斟句酌,直接把脑子里的想法倾倒出来,哪怕逻辑有点乱也没关系。
/prompt-optimize 在工具栏增加一个“高亮句子”的按钮,点击后弹出一个包含输入栏列表的调试弹窗,默认显示一个输入栏,可点击右侧的"+"按钮在下方增加多一个输入栏,点击提交按钮后,逐一遍历每个句子,与右侧的预览视图中的句子进行匹配,并以底部虚线的形式匹配标亮这些句子。新增句子之后,前面的句子的划线效果需要全部保留。在句子前面显示一个实心圆按钮(默认展示持续性脉冲扩散动画效果),点击弹出一个提示框显示对应句子以验证点击效果。实心圆按钮需悬浮于句子上层,跟随句子滑动,不要影响到原有排版(比如不能导致原本无需换行的句子换行显示)。注意输入栏中填写的句子可能是没有格式的,也可能是Markdown格式的,而预览视图里的句子为富文本格式(也即携带粗体/行内代码等)的,需做好“无格式文本”、“Markdown格式文本”对预览视图富文本的正确映射,保证能正常显示划线与圆点。
Claude Code 的主代理,会主动调用“提示词优化器” SubAgent 来完成这项任务:

第 3 步:Subagent 接单并优化
“提示词优化器” SubAgent 开始工作。它会:
检索代码:检索与当前任务有关的代码,参考和理解现有的代码实现。
重写提示词:将你杂乱的描述,转化为符合项目规范的、结构化的技术文档。
你需要做的,就是校验一下它优化后的提示词,有没有理解偏差。

第4步:你来拍板
你确认提示词无误后,经过优化的、清晰明确的提示词就会被发送给 Claude Code ,然后开始代码编写。

第5步:成果验收
看,这就是经过 “提示词优化器” Subagent 加持后的开发成果:
✅ 功能入口:工具栏增加了按钮。

✅ 交互逻辑:调试弹窗完美支持句子增删。
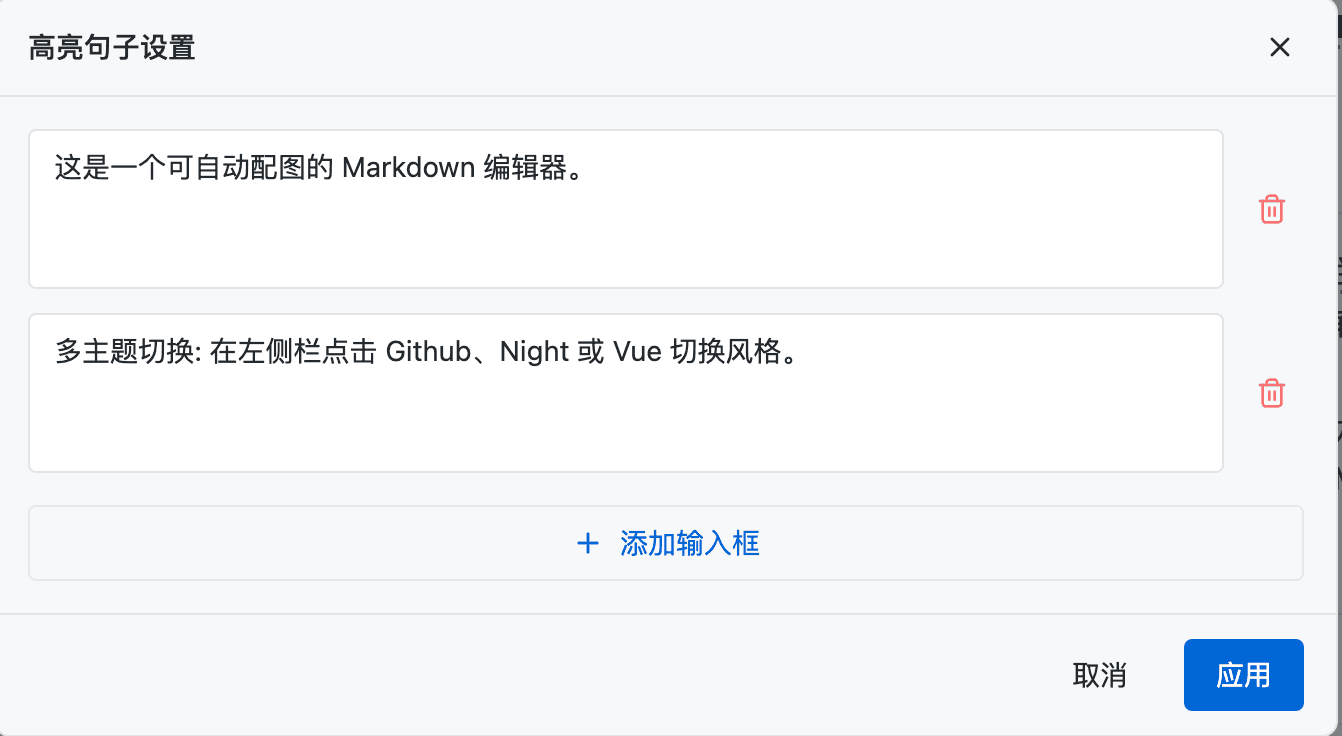
✅ 视觉细节:虚线标注、脉冲动画完全还原。

💡 给读者的建议
最后,关于 SubAgent(子代理),我有几条建议想送给你:
避免过度设计:简单的任务没必要动用 SubAgent。只有当任务需要独立上下文(防止干扰)或特殊工具权限(安全隔离)或专业化的角色设定(代码审查)时,才是组建“专家团队”的最佳时机。
权限要克制:给 Subagent 配备工具时,请务必克制一点。只负责读代码的 SubAgent,就不需要给它写文件的权利。克制的授权不仅安全,还能让 SubAgent 更专注。
先试用,后转正:别妄想一步到位。建议先在普通对话里通过自然语言调试,确认这套提示词能稳定干活后,再把它封装成 Subagent。这是成本最低的开发路径。